Ch 09. 함수 - 08. 함수 포인터
1. 함수 포인터
함수 포인터(function pointer)는 함수의 주소를 저장하는 포인터로 함수도 결국 메모리에 저장되고, 이 함수의 주소를 변수에 담아서 나중에 호출도 가능하다 에서 나온 개념으로 함수도 결국은 메모리 어딘가에 저장된 코드 블록의 시작 주소이고 이 주소를 일반 변수처럼 포인터에 저장하고, 그걸 통해 호출하도록 만들어 주는 기능이라고 보면 된다.
int add(int a, int b) {
return a + b;
}
int main() {
int result = add(3, 4); // add 함수 호출
}우리는 함수를 위와 같이 어딘가에 정의해두고 그 함수명으로 호출문을 작성해서 함수를 호출했었다.
반면 함수 포인터는
int add(int a, int b) {
return a + b;
}
int main() {
int (*funcPtr)(int, int); // "int 두 개를 받아 int를 반환하는 함수 포인터"
funcPtr = add; // add의 주소를 funcPtr에 저장
int result = funcPtr(3, 4); // 포인터로 add를 호출
std::cout << result << std::endl; // 7
}이런 사용 방법을 가지고 있다.
2. 함수 포인터의 원형
함수 포인터의 원형은
반환타입 (*함수포인터이름)(매개변수타입1, 매개변수타입2, ...);이렇게 구성되어 있다.
실 사용의 예시를 보여주면
int (*funcPtr)(int, int);과 같이 사용되며 이는 int 형 매개변수 2개를 순서대로 받아 int를 반환하는 함수 포인터 funcPtr 이라고 부를 수 있다.
반환타입 * 변수명 (매개변수 타입1, 매개변수 타입2..) 으로 선언하는게 아니라
반환타입 (* 변수명) (매개변수 타입1, 매개변수 타입2..) 으로 선언하는 이유는
반환타입 * 변수명 (매개변수 타입1, 매개변수 타입2..)이거는 함수의 선언에 해당하기 때문이다.
함수의 선언 - int * ptr (int , int);
- int형 매개변수 2개를 가지고 int* 포인터를 반환타입으로 하는 함수 ptr
=> int* ptr(int, int) = add; 이런식으로 사용하면 컴파일러는 ptr을 함수로 인식하고 있는데 add를 초기화하려고 하기에 컴파일 에러를 발생시킴
함수 포인터의 선언 - int (* ptr) (int, int)
- int형 매개변수 2개를 가지로 int를 반환타입으로 하는 함수의 주소값을 담을 함수 포인터 ptr
여기에
int add(int a, int b){
return a + b;
}이런 함수가 존재한다면 이 함수의 이름, 함수명을 통해서
funcPtr = add; // 함수의 이름은 배열의 이름처럼 decay됨
// &
funcPtr = &add;이렇게 초기화가 가능하다
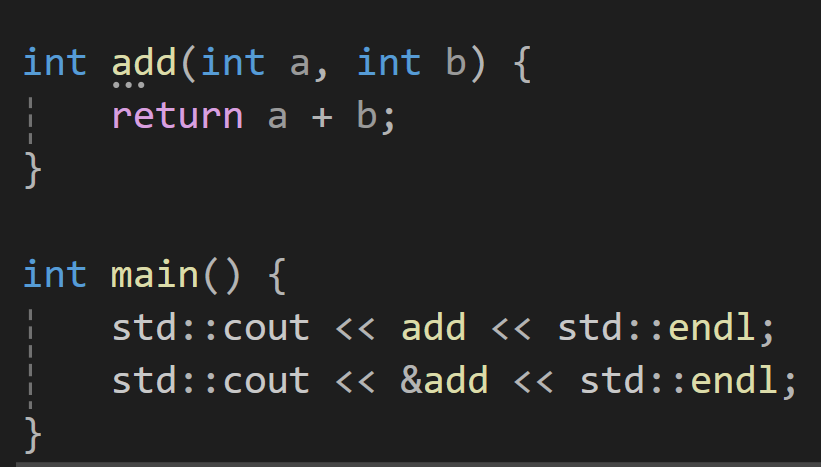

이렇게 함수 또한 함수의 이름이 함수의 주소값을 반환하는것을 확인할 수 있음
이렇게 초기화된 함수를 함수포인터를 통해 사용해보면
int result = operation(3, 4); // 일반 함수처럼 호출
int result2 = (*operation)(5, 6); // 괄호로 감싸도 동일하게 동작이런식으로 사용이 가능하다.
3. 함수 레퍼런스
함수 포인터가 가능하듯이 함수 레퍼런스 또한 가능하다.
함수 포인터보다는 상대적으로 덜 쓰이나 문법적으로 깔끔하고 안전한 코드 작성에 유용하게 사용될 수 있다.
함수 레퍼런스의 원형은
반환형 (&참조이름)(매개변수 목록) = 원래함수이름;이렇게 되어 있으며 실 사용은
int add(int a, int b) {
return a + b;
}
int main() {
// 함수 레퍼런스 선언
int (&refAdd)(int, int) = add;
}이렇게 사용된다.
호출하는 것은 원래 함수를 사용하듯이
// 마치 원래 함수처럼 호출 가능
std::cout << refAdd(3, 4) << std::endl; // 7 출력
// *역참조 연산자를 사용해서 호출도 가능
std::cout << (*refAdd)(3, 4) << std::endl; // 7 출력이렇게 호출이 가능하다.
그냥 기본 함수의 경우도 역참조 연산자를 사용해서 사용도 가능하다.
int add(int a, int b){
return a + b;
)
std::cout << add(a, b) << std::endl;
std::cout << (*add)(a, b) << std::endl; // (*add)를 하면 add가 나옴
std::cout << (*(*add))(a, b) << std::endl; // 그걸 또 (*(*add))를 하면 add가 나옴
정리해보자면
add == &add // add는 컴파일러가 &add로 자동으로 decay함
*add == add == &add // *add 했을때 함수의 이름인 add가 그대로 나옴
*(*add) == *add == add == &add // 그러기에 *(*add)하더라도 *add가 되고 그 결과도 add가 나옴이런 것도 가능하다는 것을 알고만 있자.
이는 레퍼런스이기에 무조건 초기화와 함께 사용되어야 하고 &를 사용해서 주소값을 넘겨줘서도 안되고 nullptr을 통해서 초기화도 불가능하고 초기화 된 값을 변경하는 것도 불가능하다.
int (&refAdd)(int, int); // ❌ 초기화 없이 선언 불가능
int (&refAdd)(int, int) = &add; // ❌ 주소값으로 초기화도 불가능
int (&refAdd)(int, int) = nullptr; // ❌ nullptr로 초기화하면서 선언도 불가능
int (&refAdd)(int, int) = add;
refAdd = swap; // ❌ 초기화된 값을 변경하는 것도 불가능
4. 함수 포인터 배열
이래서래 포인터의 경우는 표현하는 방식이 위치에 따라서 많이 달라지기에 한번 정리 하기위해서 함수 포인터 배열에 대해서 설명하고자 한다.
먼저 함수 포인터 배열의 사용방법은
int (*ptr[])(int, int);와 같이 사용된다.
그리고 이 내부는 각각
ptr
├── ptr[0] : 함수 포인터 → f(int, int) → int
├── ptr[1] : 함수 포인터 → g(int, int) → int
...와 같이 구성되어 있다.
여기서 나는 항상 형태에 대한 의문을 가지면서 내용을 정리하기에 여기서 조금 동떨어진 내용이지만 조금 정리해두고자 한다.
int* ptr []
int (*ptr)[]
int (*ptr[])(int, int)이 셋의 차이점은 배워왔다면 극명하게 확인할 수 있다.
근데 어떻게 구분을 해야 쉬울까.
각각의 타입은 ptr을 기준으로 읽고 () 괄호를 우선으로 읽으며 오른쪽 에서 왼쪽 순으로 해석하게 된다(컴파일러가)
하나 하나 확인해보자면
int * ptr [];
1. ptr을 기준으로 오른쪽 [] => ptr은 배열이다
2. ptr을 기준으로 왼쪽 int* => ptr은 배열이고 내부 요소는 int* 타입이다
int * ptr[3]
=> ptr → [
ptr1 → int
,ptr2 → int
,ptr3 → int
]int (*ptr)[];
1. ()를 우선으로 확인 ptr기준 오른쪽은 없기에 왼쪽 * 를 확인 => ptr은 포인터이다
2. ()외부 오른쪽을 먼저 보고 [] => 포인터 ptr은 [] 배열을 가리킨다
3. ()왼쪽을 보고 int => 포인터 ptr은 [] 배열을 가리키고 그 배열의 요소는 int형을 가진다
int (*ptr)[3]
=> ptr → [int, int, int]int (*ptr[])(int, int);
1. ()을 가장 먼저 해석, ptr기준 오른쪽을 보고[] => ptr은 [] 배열이다
2. 이제 ptr기준 왼쪽 * => ptr은 배열이고 내부 요소는 포인터이다.
3. ()외부 오른쪽을 보고 (int, int)
=> ptr은 배열이고 내부요소는 포인터이며 이는 각각 매개변수를 int타입 2개를 받고 반환형이 int이다
int (*ptr[3])(int, int);
=> ptr = [
ptr1 → int func1(int, int);
,ptr2 → int func2(int, int);
,ptr3 → int func3(int, int);
]
읽는 법은 볼때 마다 헷갈리지만..사실 그렇게 많은 가짓수가 있진 않으니까 읽는 법 자체를 보는건 컴파일러한테 맡기고 어느정도 그냥 방식을 외우도록 하자..
아무튼 함수 포인터 배열의 경우는 위와 같이 구성되어 있다.
여기서 함수 포인터를 사용한 콜백 사용에 대한 방법을 확인해 보자.
5. 함수 포인터의 콜백
1) 콜백이란
함수 호출 자체를 다른 쪽(외부)에 맡기는 프로그래밍 구조나 방식을 콜백이라고 한다
콜백 자체는 방식/구조를 말하는 것 콜백 함수는 그 구조 안에서 실제로 호출되기 위해 전달된 함수를 말하는 것이다.
이 콜백이 되기 위해서는 두가지 기준이 존재하는데
1. 함수를 함수에 전달
2. 전달된 함수를 그 함수 안에서 호출 (≠ 직접 호출 아님)
이 되어야 한다.
그리고 콜백은 어떤 함수를 실행할지 결정하는 책임을 외부(상태, 입력, 상황)에 넘기는 구조여야만 한다.
단순한 함수의 호출이라면 콜백을 성립하지 않는다.
함수를 함수에 전달
void onComplete() {
std::cout << "완료됨!" << std::endl;
}
int main() {
doSomething(onComplete); // onComplete 전달
}이렇게 함수를 함수에게 전달해야하고 이 시점에 전달된 함수가 실행되어서는 안된다.
전달된 함수를 그 함수 안에서 호출
void doSomething(void (*callback)()) {
std::cout << "작업 중..." << std::endl;
callback(); // 전달받은 함수 호출 ← 이게 콜백
}이렇게 함수 포인터로 함수를 받은 다음에 이를 통해서 함수 내부에서 호출하는게 콜백이다.
여기서 포인트는 doSomething이 직접 함수를 호출하지 않는다는 점과 실행되는 콜백함수가 고정되어 있는것이 아니라 어떤 함수를 호출할지 외부에 맡겨져 결정이 된다는 점이다.
int main() {
doSomething(onComplete); // onComplete 전달
}이렇게 외부에서 doSomething이란 함수 내부에서 어떤 함수가 실행될지를 직접 전달해서 내부에서 onComplete가 실행된다면 콜백함수가 되는 것이다.
예시를 하나 더보자
이 부분이 나는 꽤 많이 헷갈렸다.
코드를 하나 작성해보면
int add(int a, int b) {
return a + b;
}
int minus(int a, int b) {
return a + b;
}
int times(int a, int b) {
return a * b;
}
int dev(int a, int b) {
return a / b;
}이렇게 사칙연산을 해주는 함수들이 미리 구현되어 있다고 한 후에 이를 메인 함수 내부에서
int main() {
int (*callback[])(int, int) { add, minus, times, dev };
}이렇게 함수 포인터 배열을 통해서 각각 받아준다고 했을때
std::cout << callback[0](10, 2) << std::endl;
std::cout << callback[1](10, 2) << std::endl;
std::cout << callback[2](10, 2) << std::endl;
std::cout << callback[3](10, 2) << std::endl;이렇게 호출된다면 이건 콜백함수가 아니다
이는 함수를 직접호출하지 않는다! 라는 점에서는 콜백함수와 동일할 수 있으나 어떤 함수가 호출될지 이미 고정적으로 작성되어 있기에 콜백이라 할 수 없다.
#pragma warning(disable:4996)
#include <iostream>
enum struct Operations {
add, minus, times, dev, count
};
int add(int a, int b) {
return a + b;
}
int minus(int a, int b) {
return a - b; // 여기 -로 수정할게 (위 코드엔 +였어)
}
int times(int a, int b) {
return a * b;
}
int dev(int a, int b) {
return a / b;
}
int main() {
int (*callback[])(int, int) = { add, minus, times, dev };
int op;
std::cout << "원하는 연산을 선택하세요 (0: add, 1: minus, 2: times, 3: dev) : ";
std::cin >> op;
if (op >= 0 && op < (int)Operations::count) {
int a, b;
std::cout << "두 숫자를 입력하세요: ";
std::cin >> a >> b;
int result = callback[op](a, b);
std::cout << "결과: " << result << std::endl;
} else {
std::cout << "잘못된 입력입니다." << std::endl;
}
}이 코드가 진짜 콜백이 된다.
그 이유는 어떤 함수가 호출될지 std::cin >> op; 사용자의 입력에 따라 실행 시점에 결정된다
컴파일 타임(코드 작성 시점)에 고정되어 있지 않다.
함수 포인터 배열에 등록해놓고, 실행은 사용자가 고른 값에 따라 동적으로 호출된다.
6.함수 포인터의 사용
함수 포인터를 활용하는 사례를 하나 만들어보자.
우리가 만들건 게임에서 캐릭터가 데미지를 받았을때 게임 케릭터는 죽으면 게임 오버를 띄우나 몬스터의 경우는 그냥 죽었다고만 띄우는 프로그램이다.
먼저 캐릭터 구조체를 구현해보자.
캐릭터 구조체는 캐릭터의 명칭, 체력과 죽었을때 호출된 함수 포인터를 하나 받아주자.

그리고 이제 데미지 함수를 하나 구현해보자.

데미지 함수의 경우는 어떤 케릭터든 케릭터의 HP가 0 이하가 되는 경우 죽음을 표시하고 추가적으로 죽음 이펙트를 설정한 경우 해당 이펙트를 추가로 실행하기로 한다.
이제 특별한 죽음 이팩트를 위한 함수를 하나 만들어주자.

특별한건 없고 영웅이 죽었으니 게임 오버다 라는 내용을 출력해주는 함수를 만들어주자.
이제 메인 함수에서 구조체를 선언할때 몬스터 캐릭터에는 그냥 nullptr을 전달하고

영웅 캐릭터한테는 죽음 이펙트를 따로 전달해주자.

이제 damage 함수를 호출해서 캐릭터를 전달해서 hp를 다 깎아보면

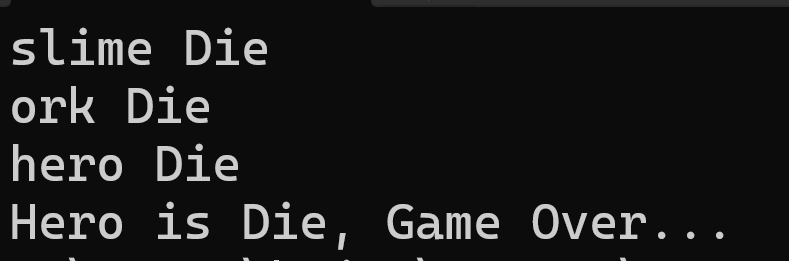
이렇게 hero만 따로 게임 오버 내용이 표출되는 것을 확인할 수 있다.
7. 추가적으로 알아야할 내용들
1) auto 타입
auto는 컴파일러에게 변수의 타입을 내가 직접 쓰지 않고, 초기화하는 값으로 알아서 추론해줘라고 명령하는 키워드로 auto를 사용하면 컴파일러가 초기값을 보고 타입을 자동으로 결정해준다.
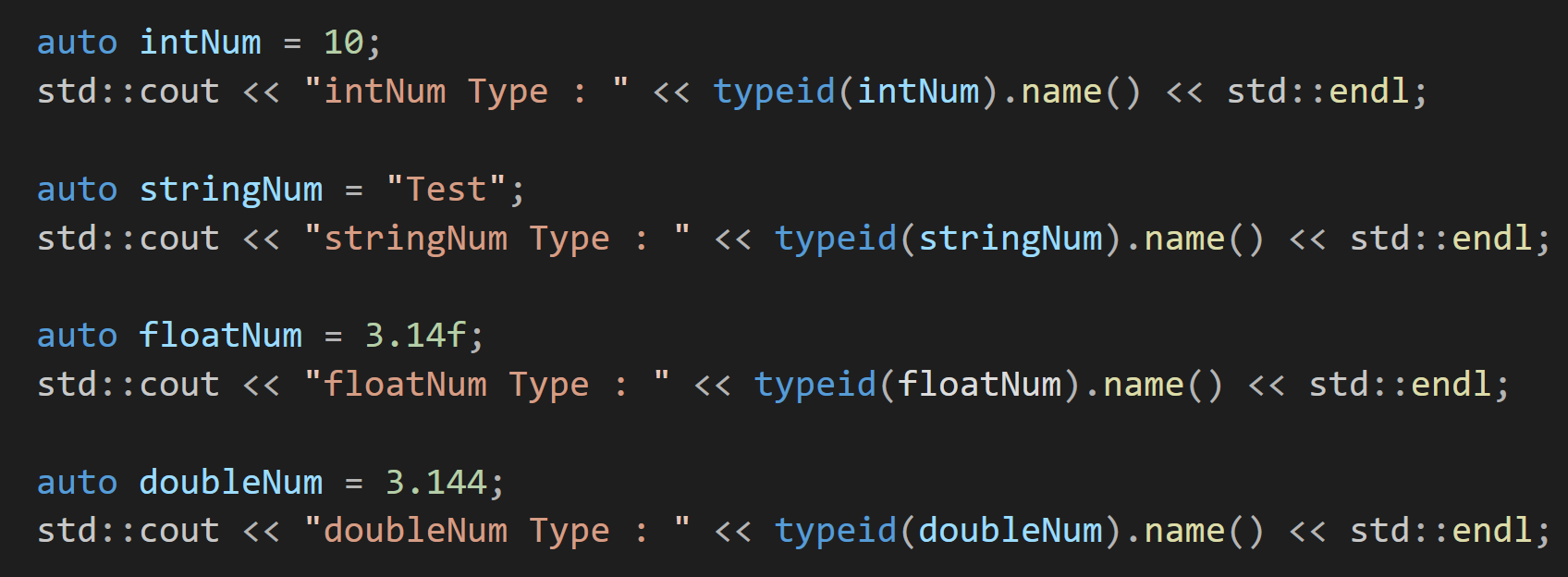

이런식으로 컴파일러가 초기화하는 값을 확인해서 타입을 알아서 추론해준다.
이렇게 추론된 타입은 파일이 실행될때는 atuo 타입이 아니고 지정한 타입으로써 실행되게 된다.
int intNum = 10;
const char* stringNum = "Test";
float floatNum = 3.14f;
double doubleNum = 3.144;
이 auto를 사용할때는 무조건 초기화가 필요하고 const와 참조가 붙을 수도 있다.
또한 함수 포인터도 auto 타입으로 자동 타입 추론이 가능하다.


이렇게 사용하면 복잡한 구조를 auto라는 걸로 단순하게 선언이 가능함을 알고 있자.
(그냥 auto로 함수 포인터 배열 같은 것은 선언이 불가능함)
2) function<반환타입(매개변수)> : 콜러블
1. 콜러블(callable)이란
함수처럼 () 연산자를 써서 호출할 수 있는 모든 것을 콜러블(callable)이라고 부른다
콜러블의 종류는
- 일반 함수 (void foo())
- 함수 포인터 (void (*fptr)())
- 람다 표현식 ([](){})
- Functor (operator() 오버로딩한 클래스)
- std::bind 결과
- 멤버 함수 포인터 (다소 복잡하지만 가능)
와 같이 전부 ()로 호출이 가능하다면 콜러블이다.
그러면 std::function<반환타입(매개변수)>는 뭘하는 것일까
2. std::function<반환타입(매개변수)>
특정 시그니처(반환타입(매개변수))를 만족하는 콜러블을 하나의 통일된 타입으로 저장할 수 있게 해주고 나중에 ()로 호출할 수 있으며 실제로 어떤 타입인지는 몰라도 상관없게 사용되는 타입으로 이를 일반화된 호출 가능 객체(wrapper), 타입 소거(type-erased) 콜러블 객체라고 부른다.
정리하자면 아무 콜러블(callable)을 저장하고 나중에 호출할 수 있게 해주는 템플릿 클래스라고 보면 된다.
이런 구체적인 설명은 머리에 잘 안들어오니 읽은걸로 하고 사용하는 방법을 보면 우선 해당 기능은 functional이라는 모듈에 포함되어 있기에 이를 include해줘야만 사용이 가능하다.

그리고 위에 제목과 같이 콜러블 함수에 맞춰 만들어주면

이렇게 담는 것이 가능하다.
이렇게 넣으면 기존에 함수 포인터를 사용하는 방식과 동일하게 사용하면 된다

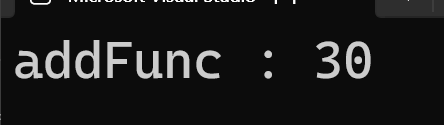
이것도 이렇게 함수 포인터 대신 할당할 수 있다는 것만 이해하고 넘어가자.
3) typedef
typedef는 기존 타입에 새 이름(alias)을 붙여주는 키워드로 길거나 복잡한 타입에 새로운 짧은 이름을 부여해서 코드를 읽기 쉽고, 유지보수하기 쉽게 만들어준다
1. typedef의 사용법
typedef 기존타입 새이름;으로 실 사용 예시를 보면
typedef unsigned int uint;
uint a = 10; // unsigned int a = 10;과 동일와 같이 사용된다.
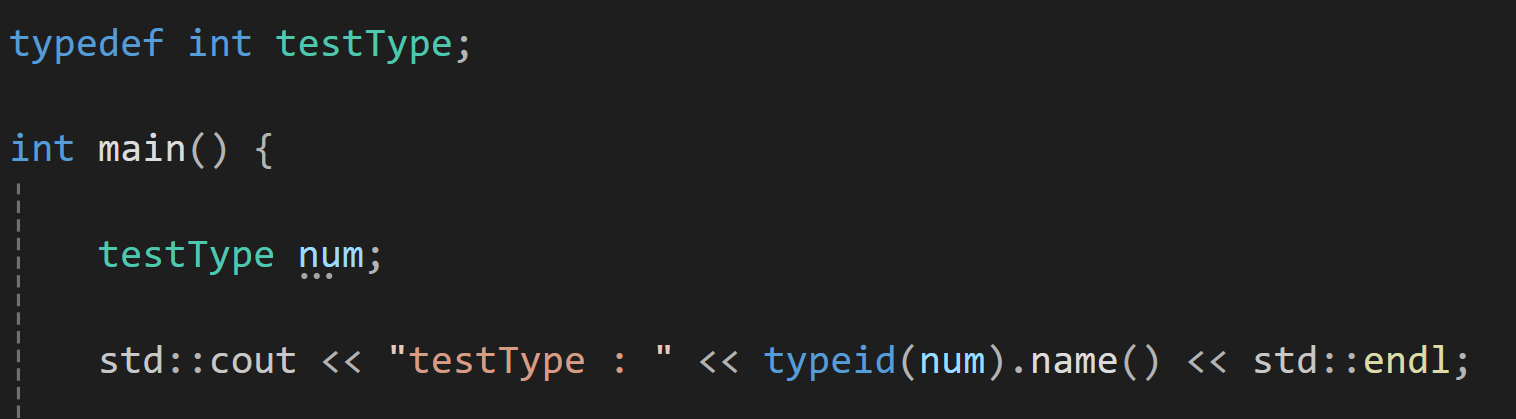
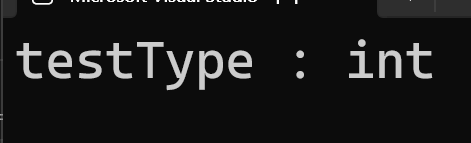
이렇게 새로 만든 타입의 이름으로 선언해도 정상적으로 선언이 되는 것을 볼 수 있다.
만약 함수 포인터의 경우라면

이렇게 typedef를 설정하고 실 사용은
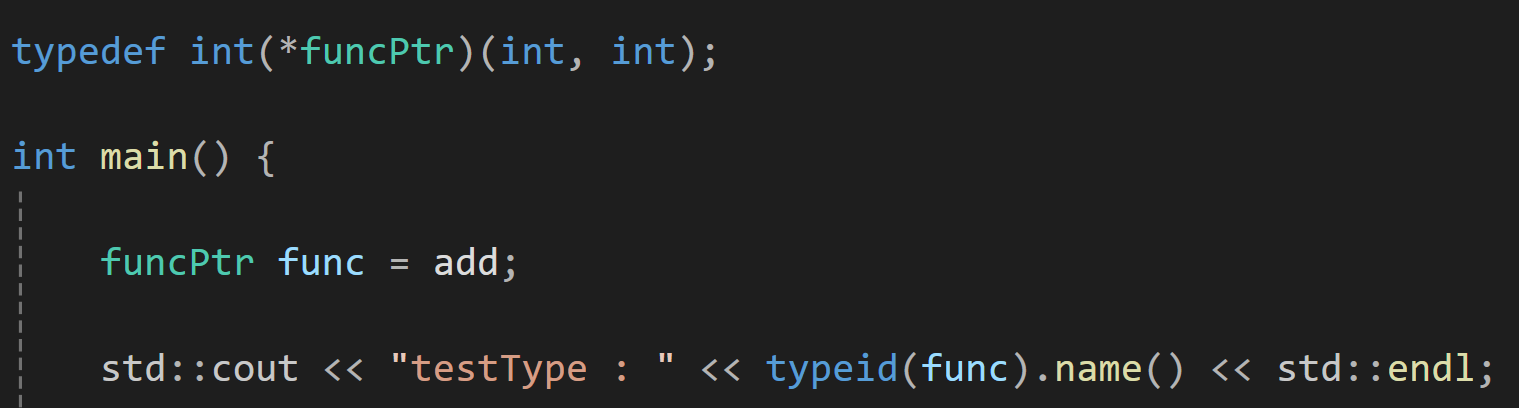
이렇게 사용하고 이 실 타입이

이렇게 함수 포인터인것을 알 수 있다.
만약 타입이

이렇게 함수 타입이라면 선언할때
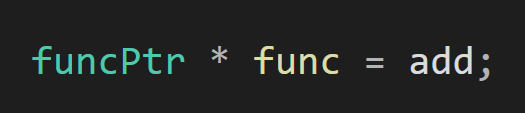
이렇게 포인터를 추가해줘야만 함수 포인터로 인식한다
만약 이렇게 안하면

이렇게 함수의 할당이 불가능하다.
이렇게 함수 포인터도 typedef를 사용해서 만들어줄 수 있다는 것을 알아두자.
4) using
using은 기존 타입에 별칭(alias)을 붙여주는 문법으로 typedef와 비슷한 역할을 한다.
하지만 typedef보다 더 표현력이 강력하고, 템플릿과 함께 훨씬 잘 쓰인다
1. using의 기본 문법
using 새이름 = 기존타입;과 같이 사용하고 이를 실 사용한 예는
using uint = unsigned int;
uint a = 10; // unsigned int a = 10;과 동일과 같이 사용한다.
만약 템플릿이 있는 타입을 사용한다면
template<typename T>
using Vector = std::vector<T>;이렇게 사용하면 된다.
여기서 함수 포인터를 using으로 사용한다면
using FuncPtr = int(*)(int, int);이렇게 사용하면 된다.
이러면 반환값 int형이고 매개변수로 int타입 두개를 받는 함수에 대해서는 FuncPtr을 통해서 선언이 가능해진다.

번외로 using은 네임스페이스를 가져오기 위해서도 사용 된다.
네임스페이스란
이름(변수, 함수, 클래스 등)에 구역을 만들어서 충돌(name collision)을 방지하는 기능으로 서로 다른 개발자/라이브러리가 같은 이름을 쓸 수도 있기 때문에 이름이 겹치지 않도록 "이름 공간(name space)"을 분리하는 장치라고 생각하면 된다.
네임스페이스의 기본 문법
namespace 네임스페이스이름 {
// 여기에 변수, 함수, 클래스 등을 선언
}과 같이 사용되며 사용 예시를 보자면
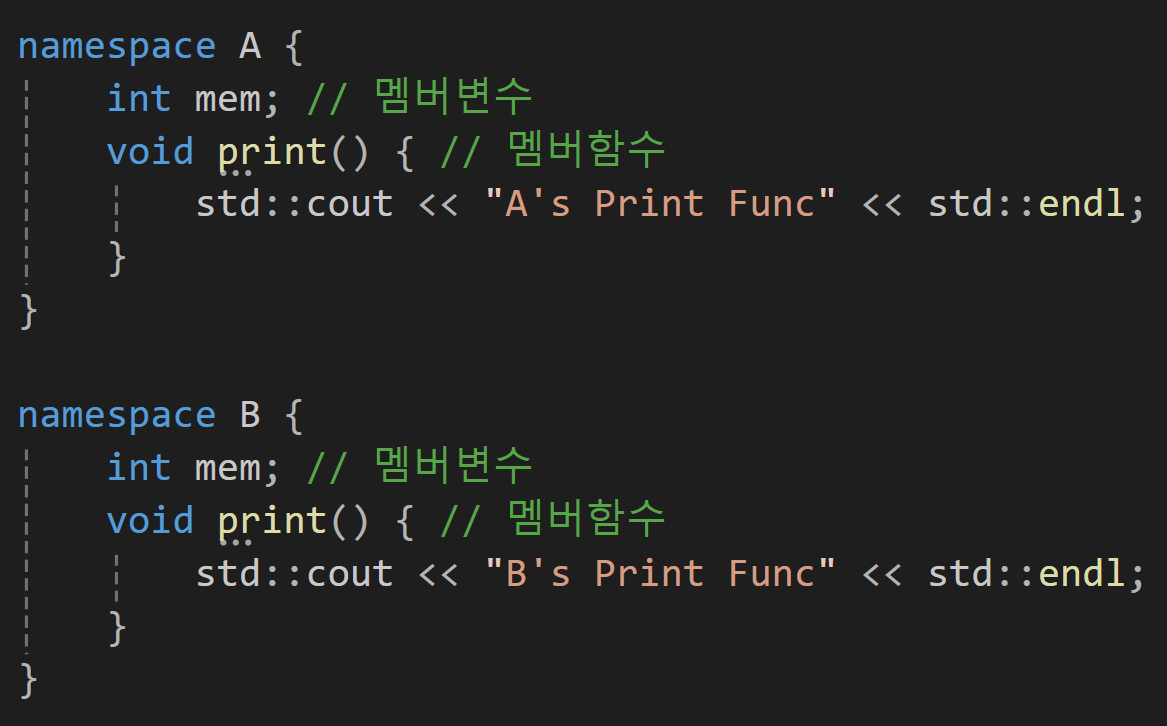
이렇게 같은 mem이라는 명칭으로 멤버 변수가 선언되어 있고 같은 print라는 명칭으로 멤버함수가 동일하게 선언되어 있는 것을 볼 수 있다.
이 함수들을 만약 그냥 mem이라던게 print로 호출하려고 한다면 컴파일러의 입장에서는 어떤 mem을 불러야할지 어떤 print를 불러야 할 지 알 수 없을 것일텐데 이를 위와 같이 namespace라는 키워드를 사용한 곳에 담아두면
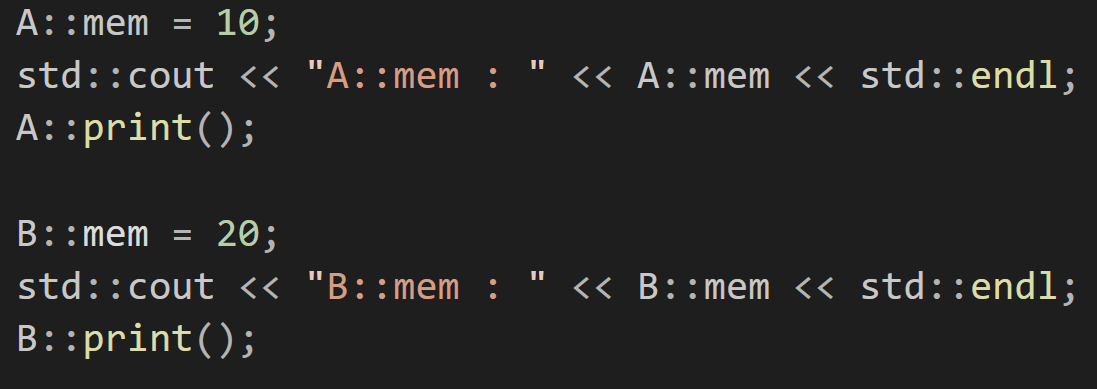
이렇게 호출해서
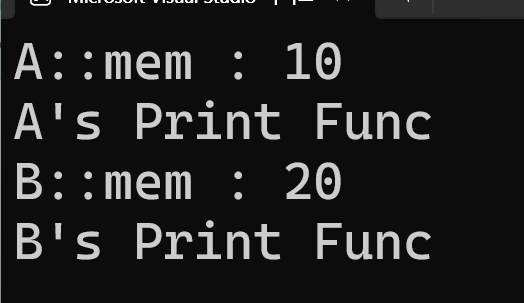
각각 원하는 대상에 할당 및 호출이 가능하게 된다.
이게 네임 스페이스이다.
기존에

이렇게 네임 스페이스를 만들었다면 이 namespace는 기존에 main함수 내부에서 사용하기 위해서는
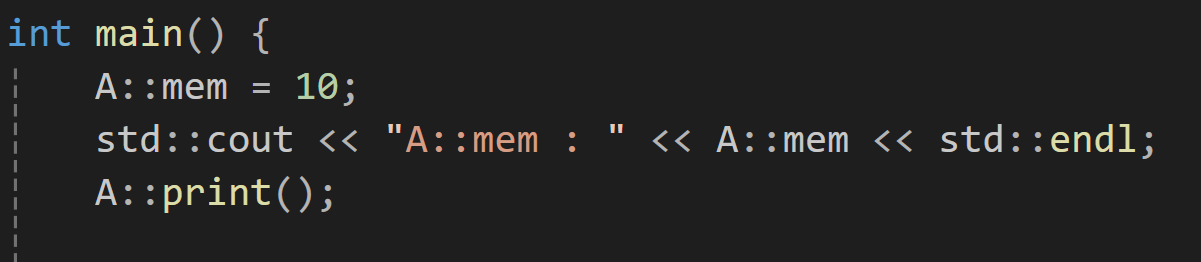
이렇게 어떤 네임 스페이스에서 가져온 멤버고 함수라고 따로 ::연산자를 넣어가면서 알려줘야만 가져와서 사용이 가능했었는데 using을 사용하면
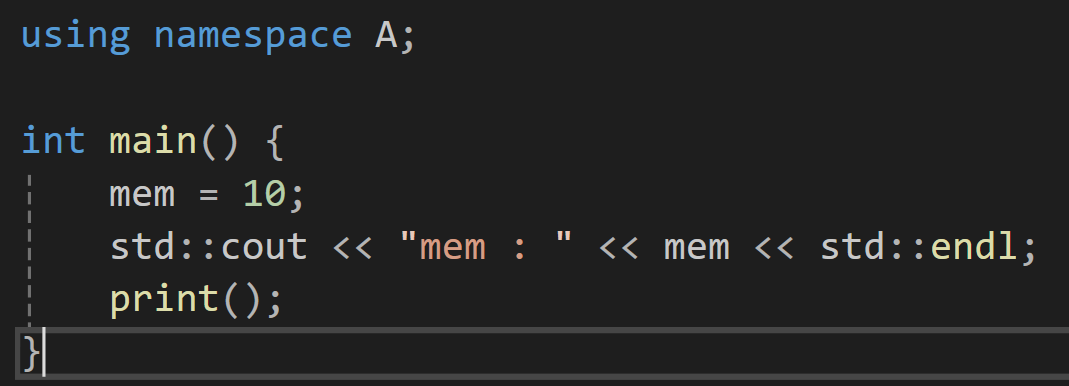
이렇게 생략이 가능하다.

하지만 이 using을 사용하면 위와 같이
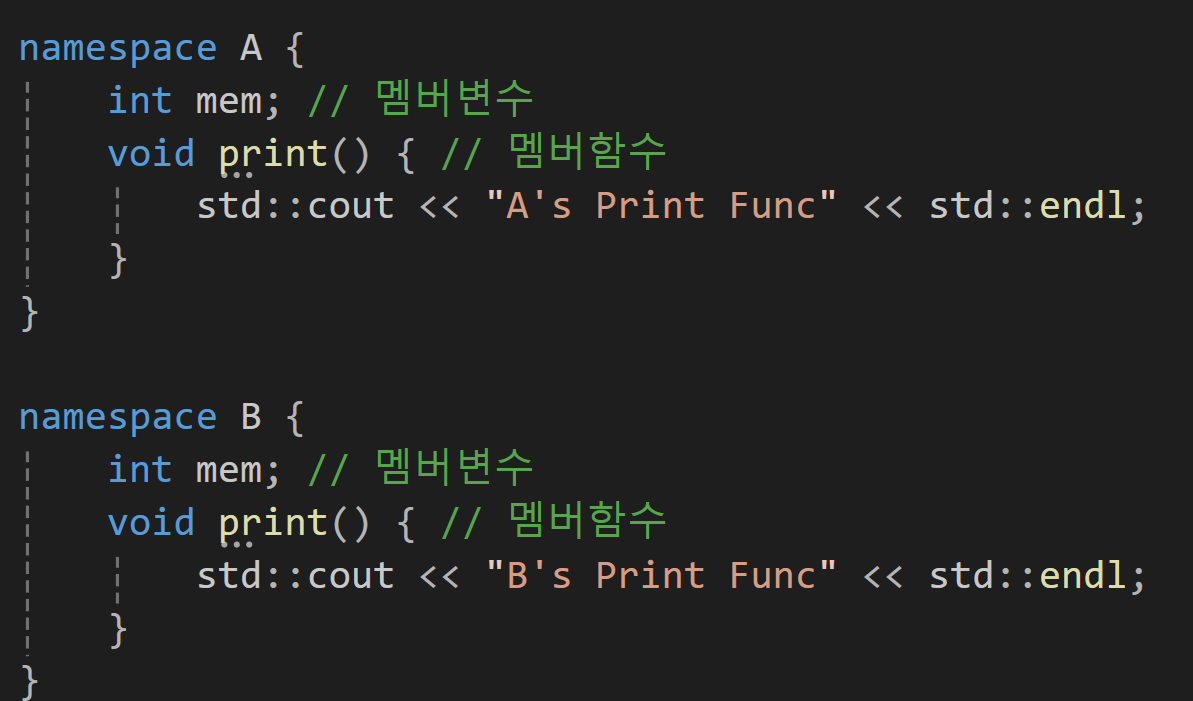
이렇게 선언되어 있는 경우
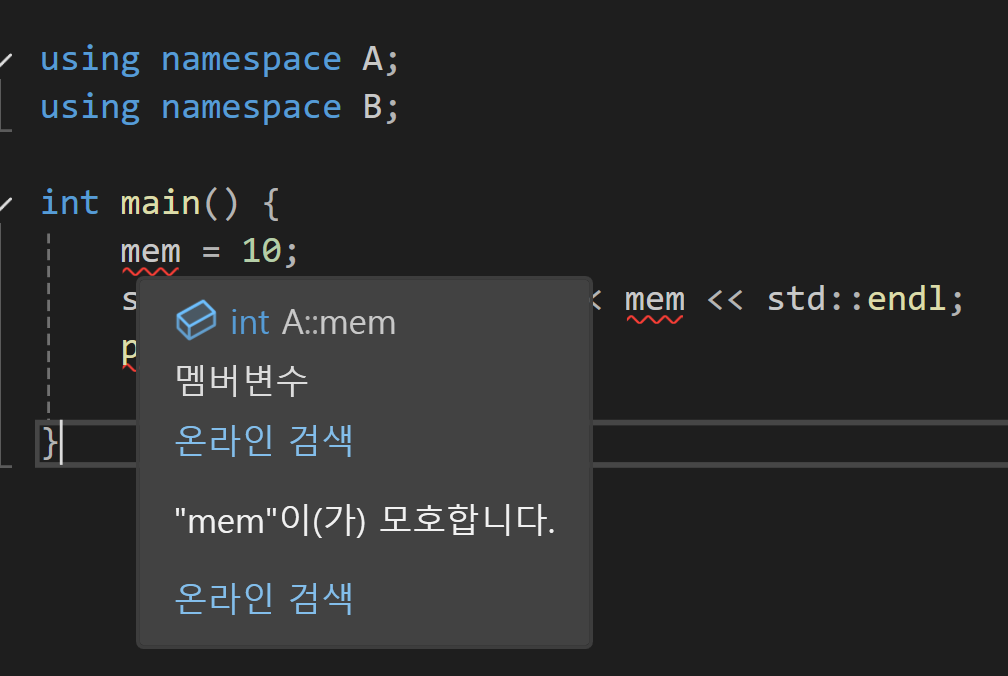
이렇게 Ambiguous 하다고 뜨니 조심히 사용해야한다.
여태 우리가 사용했던 std 또한 using을 사용하면


이렇게 생략이 가능함을 알 수 있다.
내용이 길었지만 나중에 추가적으로 설명할 수 도 있는 내용이 포함되어 있다는 점을 알아 뒀으면 한다