2024. 10. 2. 15:45ㆍProgramming Language/C
09-1 함수를 정의하고 선언하기
함수를 정의하는 것은 main함수를 정의하는 것과 비슷하다.
함수를 만드는 이유
다수의 작은 단위의 함수를 만들어서 프로그램을 작성하면 큰문제를 작게 쪼개서 해결하는 효과를 얻을수 있다.
근데 단순히 이런 이야기로 함수의 전체가 설명되지는 않지만 우선 이 정도로 이해하자.
함수에 대해서 기본적으로 어떻게 경험을 하던간에 main함수를 포함해서 함수의 크기는 작으면 작을 수록 좋다, 함수의 크기가 크다는 것은 함수가 잘못 디자인 되었다고 볼 수 있다.
보통은 내가 작성한 함수는 1000라인이 넘어가! 라고 한다면 이건 자랑할 부분이 아닌것이다.
오히려 짧은 라인으로 끝나는 함수일 수록 좋은 함수인 것이다.
그렇기에 불필요하게 큰 함수가 만들어 지지 않도록 주의해야하나 무조건 또 작다고 좋은것은 아니다.
어쩔 수 없이 커지는 함수가 생길수 있고 억지로 크기 때문에 함수를 나눠버릴 필요는 없다.
그러면함수를 나누는 기준은 어떻게 잡아야할까?
함수를 나누는 가장 좋은 기준은 하나의 함수는 하나의 기능만 담당하도록 디자인 되어야 한다.
그런데 이 하나의 기능이라는건 매우 주관적인 기준이기에 잘 정의하기가 힘들다는 것이다.
이런 주관적인 기준은 프로그래머로써 경험이 쌓인 사람의 경우는 명확한 기준을 갖고 있고 이걸 따르기 위해 노력해봐야 한다는게 중요하다.
물론 이건 공부과정에서 얻기는 힘든 스킬이다.
그러나 꾸준히 이런 과정이 필요하다는 의미이다.
함수의 형태는

와 같은 형태로 구성되어 있다.
반환형(출력), 입력형태(입력), 과 중간에 함수의 몸체를 정의하고 함수의 이름을 정의하게 된다.
함수의 입력과 출력: printf 함수도 반환을 한다
printf함수는 여태까지 단순히 호출만 했었는데


위 처럼 printf함수의 반환값을 저장해본적은 없었다.
그런데 사실 prinf함수도 사실 값을 반환하나 그 값을 사용할일이 없기에 저장한적이 없는것 뿐이다.
그래서

이 코드를 실행했을때 printf("12345\n")가 값을 반환한다는 의미는 printf호출 문장이 반환값을 대체한다는 의미이다.
예를 들어 num = 3 * 4라면 3 * 4를 넣는게 아니라 3 *4가 된 연산의 결과인 12가 3 * 4연산을 대체한다는 의미이다.
마찬가지로 printf()함수의 결과로 반환값이 생성된다면 그 반환값이 prinft()문을 대체해서 num1에 저장된다는 의미이다.
결과 적으로 printf("12345\n")라는 문장의 반환값이 6이 나오면 저 위의 문장은 함수 호출 후에

으로 인식이 된다.
이게 값의 반환이다.
만약 func() 라는 함수의 반환 값이 10인 경우라면 반환되었을때 func()라는 함수가 10으로 대체된다라고 이해하면 된다.
그래서 사실 printf의 반환값의 의미는 출력된 문자의 길이를 반환한다.
1, 2, 3, 4, 5,\n(\n은 한문자이다)으로 6개가 출력된다.
함수의 구분
그러면 이제부터 먼저 함수의 구분을 나눠야한다
함수의 유형은 전달인자와 반환값의 유무에 따라서 아래 4개의 유형으로 나뉜다.
- 전달인자가 있고, 반환값이 있다 (전달인자(O) / 반환값(O))
- 전달인자가 있고, 반환값이 없다 (전달인자(O) / 반환값(X))
- 전달인자가 없고, 반환값이 있다 (전달인자(X) / 반환값(O))
- 전달인자가 없고, 반환값이 없다 (전달인자(X) / 반환값(X))
전달인자 반환값 모두 있는 경우
먼저 아래와 같은 요구사항이 있다고 보자.
전달인자는 int형 정수 두개이며, 이 두가지를 사용해서 덧셈을 한다.
덧셈의 결과는 int형으로 반환된다.
마지막으로 함수 명은 Add로 정의한다.
여기서 "이 두가지를 사용해서 덧셈을 한다"는 기능에 대한 내용이기에 함수 내용에 들어갈 부분이고 "덧셈의 결과는 int형으로 반환한다"를 보았을때 int형 반환타입을 가지게 될것이고 "함수 명은 Add로 정의한다"를 보았을대 Add라는 함수명을 사용하고 그 전달인자는 int형 변수 두개로 설정하면 될것 같다.
그걸 토대로 함수를 생성해보면

와 같이 구성될 것이다.
이렇게 Add라는 함수가 생성 되었고 메인 함수에서 이 Add라는 함수를 사용할 수 있게 된다.
그러면 정의된 함수를 호출하는 코드를 보자.

내용은 너무 기본적인 내용이라서 궂이 설명하지 않겠다.
결과는 예상 되는대로 순서대로 7, 11이 출력될 것이다.

전달인자나 반환값이 존재하지 않는 경우
전달 인자나 반환값이 무조건 있어야 하는건 아니다.
값이 불필요하다면 반환을 하지 않게 정의해도 되고 전달인자가 필요하지 않다면 넣지 않게 정의하면 된다.
먼저 전달인자가 있고, 반환값이 없는 경우의 코드를 보자.
전달인자(O) / 반환값(X)

이런 경우에는 해당 함수의 결과를 변수에 대입하는 연산은 할 수 없다 (ex, result = ShowAddResult(5); - 불가능함)
그렇기에 이 경우엔 그냥 함수를 호출만 하면 내부의 로직을 실행시켜주게 된다.
전달인자(X) / 반환값(O)

이 경우는 대입연산이 가능하고 함수를 호출할때 인자를 전달해줄 필요도 없다.
전달인자(X) / 반환값(X)

이건 그냥 단순하게 두개의 문자열을 호출해준다.
이 함수가 호출되면 문자열을 출력하고 종료만 해주기에 전달, 반환 값도 필요 없게 된다.
4가지 함수 유형을 조합한 예제


이 코드의 결과는

와 같다.
값을 반환하지 않는 return
부가적인 문법에 대한 내용인데 return에는 두가지 의미가 있다.
하나는 값을 반환하는 의미가 있고, 함수의 종료의 의미도 있다.
그래서 그냥 값을 반환하지 않고 빠져나가기만 하는 경우로 사용되는 return도 있다.
void NoReturnType(int num){
if(num < 0){
return;
}
....
}과 같이 return 을 사용하기도 한다.
함수의 정의와 그에 따른 원형의 선언
함수는 정의의 위치에 따라서 함수를 인식하지 못하는 경우가 있어 배치가 중요하다 .

이 코드는 문제 없이 Increment함수의 생성을 인식하고 main함수에서 Increment함수를 호출한다
그런데

이 코드는

해당 오류를 생성한다.
그 이유는 컴파일러가 위에서 아래로 컴파일을 진행하기 때문에 메인함수를 먼저 읽고 그 안에 있는 Increment를 읽었을때 이 Increment함수가 컴파일 되지 않았기에 에러를 발생한다.
이렇게 컴파일되지 않은 함수는 호출이 불가능하다.
그런데 보통은 중요도에 따라서 함수를 배치하기 마련인데 메인함수의 아래에 위치하면 인지하지 못하기에 함수의 정보를 먼저 제공한다.
"이 함수는 나중에 나올거야" 라고 컴파일러한테 제공해주면 이후에 등장하는 함수의 호출 문장이 컴파일 가능하도록 도울 수 있다.
이렇게 제공되는 함수의 정보를 가리켜 "함수의 선언"이라고 한다.
함수의 선언은 아래와 같이 사용한다.
반환형 함수명 (매개변수 타입 [매개변수명])
과 같이 사용한다.

이렇게 사용하고 나중에 나올 함수의 선언 문과 비슷하지만 변수명은 생략해도 괜찮다.

09-2 변수의 존재기간과 접근범위 1
변수는 생성 시점과 생성 위치에 따라서 존재하는 기간과 접근할 수 있는 기간이 다르게 설정된다.
하나의 예로는 함수내에 선언된 변수는 함수 외부에서 접근이 불가능하다라는 점이 있다.
이런 변수의 존재기관과 접근 범위에 대해 이해해보자.
함수 내에서만 존재 및 접근 가능한 지역변수


위 처럼 함수 내에 선언된 변수(사실 중괄호의 내부에 선언된 모든 변수)를 지역변수라고 한다
지역 변수는 선언된 이후부터 함수 내에서만 접근이 가능하다.
한 지역 내에 동일한 이름의 변수를 선언하는 것은 불가능하다
그러나 다른지역(다른함수)에서 동일한 변수명을 선언하는 것은 가능하다.
해당지역을 빠져나가면(함수가 종료되면) 그 지역에서 선언된 지역변수는 소멸되고 호출 될때마다 새로 생성된다.
물론 for문, while문등을 사용해서 그 내부에 선언된 변수의 경우도 지역변수이다.
반복문을 실행할때 생성되어 회차별로 종료될때마다 소멸되고 생성된다.
그리고

이것 처럼 지역 내부에 새로운 지역을 생성해서(중괄호 내부의 중괄호가 있다면) 동일한 변수명으로 변수를 선언하는 것도 가능하다.(물론 이 방법은 좋은 방법은 아니지만..)

이렇게 내부 범위에 num을 선언하면 외부에서 선언한 num을 덮어씌운다.
그래서 외부의 num을 내부에서 다시 동일하게 생성한 경우는 외부의 num보다 내부의 num에 우선순위를 가진다.
그래서 내부의 num을 선언하는 부분만 주석처리를 해보면


이렇게 동일한 변수를 출력하는 것을 볼 수 있다.
지역변수의 일종일 매개변수
그리고 함수를 호출할때 전달되는 인자를 저장하는 변수를 매개변수라고 했었는데

이 매개변수가 중괄호 안에 존재하지는 않지만 중괄호 외부로 벗어나면 소멸되는 지역변수와 비슷하다.
사실 함수가 선언될때 가장 먼저 선언되는 지역변수라고 볼 수 도 있다.
그리고 동일하게 중괄호 외부로 나갈때 소멸되는 변수이다.
09-3 변수의 존재기간과 접근범위 2
변수의 종류는 지역변수, 전역변수 , static변수 , register변수가 있다.
위에선 그 중 가장 내용이 많은 지역변수에 대해서 보았고 이제 그 외의 변수의 종류에 대해서 알아보자.
전역변수의 이해와 선언법
전역변수는 함수 외부에 선언된다.
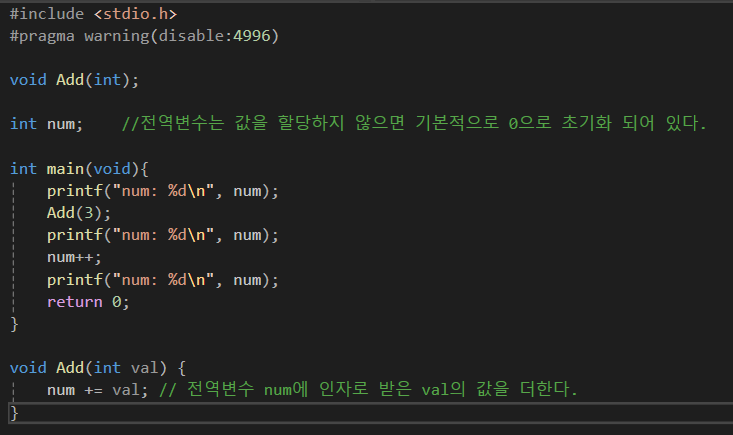
보통 프로그램의 시작과 동시에 메모리 공간에 할당되어 종료까지 존재한다.
별도의 값을 지정하지 않는다면 0으로 초기화된다.
프로그램의 어디에서나 접근이 가능하다.

그리고 전에 지역변수에서와 마찬가지로 함수의 내부에 동일한 이름으로 변수가 선언된다면 그 지역 내에선 지역변수가 전역변수보다 우선순위를 갖기에 전역변수읽지 않고 지역변수를 먼저 읽는다(전역변수가 읽히지 않음).


전역변수, 많이 사용해도 되나
전역변수는 사용이 쉽기에 많이 쓰고 싶겠지만 사실 전역변수는 안쓰면 안쓸수록 좋다.
전역변수는 프로그램의 전체 영역의 어디서든 접근이 가능하기에 개발하면서 전역변수의 변경은 전체 프로그램의 변경으로 이어질 수 있기에 전역변수에 의존적인 코드는 프로그램의 전체 영역에서 찾아야만 한다.
지역변수에 Static을 추가한 Static변수

static 변수는 변수의 타입 앞에 static 키워드를 붙여서 생성한다.
이 static키워드는 지역변수에도 전역변수에도 붙일 수 있다.
지금 여기서 선언하는 static변수는 변수 그자체보다도 static에 조금 더 집중한 설명이 될 것이다.
static 변수는 선언한 함수의 내부에서만 접근이 가능하다(지역 변수의 특징)
처음 생성될때 딱 1회 초기화 되고 프로그램 종료시까지 메모리 공간에 존재한다(전역변수의 특징을 가지고 있음).

이건 사실 지역변수 + a 의 성격을 가진것 같겠지만, 전역변수 + a의 성격을 가진다고 보는게 맞다.
static이라는 키워드를 붙여주면서 함수 내부로 들어갈 수 있게 되었다고 생각하는게 좋다.
우리가 전역변수를 사용해야할 대표적인 이유가 두가지가 있는데 첫번째로 그 값을 계속 유지하고 싶을때와 두번쨰론, 어디서든 그 값에 접근할 수 있게하기 위해서이다.
보통은 첫번째 이유가 많이 필요한 경우가 많다.
두번째 이유에서는 꼭 우리가 어디서든 필요한 번수가 필요한가 의문을 갖고 다른 방법으로 해결하는 경우가 많기 떄문이다.
그렇기에 아예 썡 전역변수를 사용하기 보다는 static변수를 사용해서 사용 공간을 제한한 상태에서 값을 유지시키는게 조금더 안전한 방식이 될 수 있다.

이 static변수는 컴파일러가 프로그램이 시작과 동시에 메모리 공간에 값을 초기화하면서 공간에 할당해둔다.
즉, main함수가 선언되기 이전에 해당 static변수를 메모리공간에 올리고 초기화한 후에 static 변수를 할당한 라인은 없다고 보면 된다.
저 함수가 호출되면 값이 생성될것 같지만 그게 아니라 함수가 호출되기도 이전에 메모리 공간에 올라간 후, 저 함수에서 사라진다. 전역변수가 되어 버리지만 저 함수 내부에서만 사용이 가능하다.
그래서 함수가 호출될때마다 새로 초기화가 된다고 생각하는게 아니라서 함수가 선언될때 그 값은 유지가 되는 상태가 된다.
이 static 지역변수는 매우 중요하다... 잘알아두자!!(전역변수를 대체할 수 있는 대체제가 될 수 있을 것이다)
보다 빠르게, register 변수
컴퓨터에서 CPU를 볼 때 system programmer들은 register set을 중요하게 본다고 한다.
왜냐면 register의 성향에 따라서 CPU의 성격이 결정되기 때문이다.
그럼 register란 무엇인가?
CPU안에 아주 깊숙히 실질적으로 연산을 담당하는 장치를 ALU라고 하는데, 아주 가까이 존재하는 메모리가 register이다.
CPU를 보면 메모리가격을 측정할 때 밖으로 나갈 수록 가격은 싸지고 메모리는 싸지기에 메모리 용량이 커진다.
그런데 안으로 들어갈 수 록 얼마나 ALU에 가깝냐에 따라서 가격이 달라진다.
그렇기에 가격이 CPU와 가까운 순서대로 값이 비싸진다.(register > cache > RAM > H/D)
결과적으로 register가 많이 달려 있을 수록 그 만큼 성능좋은 프로그램을 만들수가 있고 cache가 커져도 그 만큼 프로그램의 성능을 좋게 할 수 있다.
아무튼 이 register라는 영역이 중요한게, 컴파일러가 컴파일 할때 이 register를 어떻게 사용할것인지 register의 배치도 고민을 해가면서 output(실행파일을)을 만들어 낸다.
그렇기에 register는 고가이고 그 크기가 작고 중요하다, 그런데 잘 사용해야한다.
접근이 가장 빠르기에 메모리를 놀려도 안좋고 너무 많이 사용해도 좋지 않다.
그 register에 적절한 빈도로 사용하게 만든 바이너리 코드가 제일 좋은 프로그램이다.
물론 이건 우리가 이걸 관리할 수는 없고 컴파일러가 레지스터를 잘 활용하도록 바이너리 파일을 잘 만들어 내야만 하는 것이다.
그런데 우리가 컴파일러에게 힌트를 줄 수 있다.

컴파일러에게 이 변수는 빈번하게 사용하게 되니까 가장 빠른 레지스터에 저장하는게 성능향상에 도움이 될거야 라고 힌트를 주는 것이다.
우리가 컴파일러한테 야 이거 꼭써! 라고 할 수 없다.
그렇기에 컴파일러는 이를 무시하기도 한다(사실 많이 무시된다, 컴파일러가 이미 충분히 발전하고 똑똑해졌기에 무시해버리고 자기가 최적화해서 코드를 바이너리 파일로 만들기도 한다).
그런데 어쨋든 이런 문법이 있기에 설명 해준다고 한다.
긎이 우리가 이걸 어떻게하면 컴파일러가 접근하게 할까? 라는 의문과 해결을 할필요 없다...
왠만하면 컴파일러가 당신보다 훨씬 잘만들것이기에 그냥 이해만 하면 된다.
09-4 재귀함수에 대한 이해
재귀 함수는 어려울 수 있다.
c언어의 전반에서 이 재귀함수를 이해해야만 하는 것은 아니다.
나중에 알고리즘, 자료구조 등에서 사용되기는 하지만 당장은 이해하지 못해도 상관은 없다.
그래도 이해하고 싶은데 이해가 안된다면 시간을 두고 여러번 읽어보면서 이해해보자.
재귀함수의 기본적인 이해

이 함수를 봤을때 Recursive라는 함수를 정의하고 있는데 내부에 보면 정의하는 중에 함수를 호출하고 있다.
이렇게 Recursive함수 내에서 Recursive함수를 다시 호출 할 수 있는 이유가 있다.
그 이유는 우리가 컴파일할때 Recursive함수의 바이너리(메모리의 올라가는 형태의 코드)코드가 만들어진다.
그러면 이 코드가 메모리 공간에 올라가야(저장해야) 실행이 가능하다.
그래야만 메인메모리에 올라가서 CPU가 이 함수를 구성하는 명령문을 하나씩 가져가서 실행을 하게될 것이다.
그니까 CPU가 이 함수에 바이너리 코드를 하나씩 가져다가 실행을 한다.
얘가 그냥 통쨰로 실행이 되는게 아니기 때문에 실제로 재귀함수의 호출이 가능한 이유는 이 함수가 메모리 공간에 존재할 수 도 존재하지 않을 수도 있다.
뭐가 됐든 간에, 오리지널 바이너리가 실행이 되는게 아니라 이 바이너리가 다른 영역으로 카피되어 실행된다.
(
함수에 대한 코드는 프로그램이 실행될때 메모리의 텍스트 영역에 저장되고
이게 호출되면 이 함수의 복사본을 스택 영역으로 가져와서 실행한다.
함수가 실행될때는 이미 텍스트 영역에 함수는 완성된 채로 저장 되어 있기에 함수 내부에서 해당 함수를 다시 부른다고 해서 이 함수는 아직 생성이 완료되지 않았기에 부를 수 없어! 라고 하는게 아니라 원본을 긁어다가 복사해서 호출된 위치에서 다시 생성한다 그렇기에 C언어에서 재귀함수의 실행이 가능한 것이다.
)
이게 볼때 이상할 수 있는데 사실 함수라는건 정의할때 하나만 생성되고 그걸 갖고 한번 사용하고 쓰고 다시 불러서 쓰는 형태가 아니라 한번 선언해두면 그 틀을 가지고 여러번 찍어낸다고 생각하는게 좋다.
그렇기에 함수를 호출하면서 내부에 함수를 호출해서 다시 이 함수가 호출되고 하는 형태는 호출하면서 시작 부분으로 되돌아가는게 아니라 호출하면 새로운 함수를 다시 생성해서 읽어들이다가 그 내부에 다시 호출문을 만나면 새로운 함수를 또 생성해서 호출한다고 보는게 맞다.
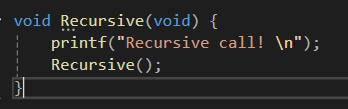
이 함수가 호출되어 실행하다 내부에 Recursive()를 만나면 다시

Recursive()함수를 생성한 후에 다시 Recursive()를 만나면 다시 생성하는 방법으로 실행된다.
이렇게 자기 자신을 재 호출하는 형태로 정의된 함수를 가리켜 재귀 함수라고 한다.
탈출조건이 존재하는 재귀함수의 예
그런에 이 재귀함수에서는 탈출 조건을 만들어 줘야지만 재귀함수를 종료할 수 있다.

이 함수를 보면 인자로 받는 num이 함수 내부에서 0과 같거나 작아질때까지 재귀함수를 호출하는데 인자를 -1 하여 전달인자의 값을 1씩 줄여가면서 재귀함수를 호출하면서 전달 인자가 0과 같거나 작아지면 이 재귀함수를 종료한다.

재귀함수의 디자인 사례
재귀 함수를 사용해서 해결하는 수학적인 한 예를 보여주려고 한다.
혹시 수학에서 팩토리얼이라는 것을 아는가
n팩토리얼 이란 것은 n부터 1까지의 숫자를 곱한 결과를 의미하고 이를 n!으로 표현한다.
\[ n! = n \times (n-1) \times (n-2) \times \cdots \times 2 \times 1 \]
그리고 n-1팩토리얼은 \[ (n-1)! = (n-1) \times (n-2) \times \cdots \times 2 \times 1 \]
과 같은 내용을 갖는다.
그렇기에 \( n! \)은 \( n \times (n-1)! \)로 표현이 가능하다
우리가 아는 팩토리얼은 결국 재귀적인 성격을 갖고 있다고 할 수 있다.
이걸 수학적 표현으로 작성해보면
\[ f(n) = \begin {cases} n \times f(n-1) & \dots n \geq 1 \newline 1 & \dots n=0 \end{cases} \]
로 표현할 수 있다.
이걸 코드로 작성해보면

과 같이 작성할 수 있다.
이걸 사용하는 전체 코드를 보면

과 같이 작성할 수 있고 이에 대한 실행은

과 같이 결과를 보여준다.
'Programming Language > C' 카테고리의 다른 글
| 열혈C - Chapter 12 포인터의 이해 (0) | 2024.10.03 |
|---|---|
| 열혈C - Chapter 11 1차원 배열 (0) | 2024.10.03 |
| 모두의 코드 - 12 - 1, 2, 3. 포인터는 영희이다! (포인터) (0) | 2024.09.30 |
| 모두의 코드 - 10. 연예인 캐스팅(?) (C 언어에서의 형 변환), 11 - 1. C 언어의 아파트 (배열), 상수, 11 - 2. C 언어의 아파트2 (고차원의 배열) (0) | 2024.09.25 |
| 모두의 코드 - 6. 만약에...(if 문), 7. 뱅글 뱅글 (for, while), 8. 우분투 리눅스에서 C 프로그래밍 하기, 9. 만약에... 2탄 (switch 문) (0) | 2024.09.25 |