2024. 11. 17. 16:41ㆍProgramming Language/C
여태까지는 하나의 소스파일안에 모든 것을 다 넣었었다.
그런데 사실 프로그래밍을 하다 보면 하나의 파일안에 모두 다 넣어놓지는 않는다.
여러개의 파일들이 만들어지고 이게 하나의 프로그램을 만들게 된다.
그러면 왜 파일을 나눌까?
파일을 나누는 이유는 관리의 용이성을 위해서이다.
파일을 나누는 이점을 살펴보자면 한사람이 하나의 프로그램을 만든다고 생각하지만 실제로는 다수의 사람이 하나의 프로그램을 개발하기 마련이다.
그러면 보통 각자가 파일을 만들고 하나로 묶어서(적절한 위치에 배치시킨다) 컴파일해서 하나의 실행파일을 만들어내는 것이다.
단순하게 협업을 위해서이다 라고 만 생각해도 파일을 분리해서 프로그램을 개발하는게 더 자연스럽지 않을까.
그리고 소스코드 하나에 1만개 이상의 라인을 만들었다고 한다면 어떤 코드가 어떤 기능을 하는지 찾기가 매우 불편하다.
이때 용도별, 기능별, 목적별로 파일을 분리해둔다면 내가 어떤 기능을 수정하려고 했을때 어떤 곳에 존재하는지 찾기가 훨씬 용이해진다는 것이다.
그렇기에 파일을 나누지 않고 프로그램을 만든다는 것은 사실 말이 안되는 것이다.
그렇기에 이번 챕터에서는 파일을 분리하는 방법과 그로 인해서 중요성이 인지되는 헤더파일에 대해서 이해해보고 생성하는 방법에 대해서 이야기 해보자.
27-1 파일의 분할
그래서 C언어를 공부했을때 파일을 2개 이상 나누는 방법을 모른다고 한다면 그건 잘못된 것이다.
아주 간단한 프로그램을 만든다고 하더라도 파일을 분할하는 습관, 헤더파일을 디자인하는 습관을 들여야한다.
그렇기에 이 방법을 잘 알아두도록 하자.
파일을 그냥 나눠도 될까?
단순하게 먼저 생각해보자면

이런 소스코드가 존재한다고 할때 너무 커져서 파일을 나눠야 한다고 했을때 전역변수/함수/메인함수를 기준으로 파일을 나눠보자.



이렇게 나눠서 하나의 프로젝트 안에 모두 담았다고 한다면 컴파일하면 컴파일이 될까?
안된다.
단순히 나누었다는 사실은 문제가 없는데 나누고 나서 컴파일러의 특성에 의해서 문제가 발생하는데, 컴파일러는 파일 단위로 컴파일을 하기에 num.c, func.c, main.c 모두 컴파일을 하는데 별도의 컴파일을 하는데 어떻게 하나의 실행파일로 만들어 줄수 있는 것일까.
그에 대한 해답이 바로 링커 이다.
이 링커에 의해 링킹의 과정을 거치면 그게 하나의 실행파일로 만들어준다.
그래서 컴파일러는 파일단위로 컴파일을 한다.
그렇기에 func.c에 존재하는 num(num.c에 존재하는)가 어디에 있는지 이해하지 못한다.
그 이유는 위에서 말했다 싶이 컴파일러는 파일단위로 컴파일을 하기 때문이다.
컴파일러는 이전에 컴파일했던 정보를 기반으로 다음 컴파일을 진행하지 않는다는 것이다.
그렇기 때문에 func.c와 main.c 모두 각 파일에 존재하지 않는다면 뭐가 어디에 있는지 모르겠다고 오류를 발생시킨다.
그렇기에 나눴으면 각 파일이 어디에 위치하는지 컴파일러한테 남겨놔야 하고 파일단위로 컴파일 하기에 각 파일에 필요한 정보들이 어디에 존재하는지 알려주고 컴파일을 해야한다.
그러니까 파일을 그냥 나눠도 될까요? 그게 만약 그냥 파일만 나누기만 하면 끝인가요? 라면 그에 대한 대답은 "아니요"이다.
외부 선언 및 정의 사실을 컴파일러에게 알려줘야한다!
외부에 선언되어 있다, 정의되어 있다를 컴파일러에게 알리기 위해서는 파일의 상단에 키워드 extern을 사용해서 알려줘야 한다.
//num.c
int num = 0;
//func.c
extern int num;
void Increment(void){
num++;
}
int GetNum(void){
retunr num;
}
//main.c
extern void Increment(void);
extern int GetNum(voud);
int main(void){
printf("num: %d \n", GetNum());
Increment();
return 0;
}
여기서 extern은 어떤 것이 밖에 어딘가에 있다! 를 알려주는 것이다.
func.c를 보면 int num이란 변수가 외부에 어디인가에 있어 그니까 걱정말고 그냥 컴파일해! 라고 알려주는 부분이
extern int num;인것이다.
그러면 컴파일러가 "아 있어?"라고 하면서 그냥 문제 없이 컴파일을 해준다.
그런데 여기서 main.c의 경우에 있는 함수의 extern선언은 사실 extern을 생략해도 된다.
이 extern을 생략하면 사실 함수의 원형선언과 동일해지는데, 사실 이 함수의 원형 선언 또한 어딘가에 있다는걸 컴파일러에게 전달하는 것이기에 동일하게 작성해도, extern은 생략해도 문제가 없다.
그런데 보통 보편적으로는 extern을 사용해주면 함수의 위치(내부에 있는지 외부에 있는지)를 구분할 수 있는 용도로라도 작성하는 경우가 있다고 한다.(개인적으로 봤을땐 extern이 있을때 코드의 가독성이 좋아질것 같기도 하다.)
전역변수의 static 선언의 의미
그러면 이제 static 선언에 대해서 알아보자.
// static 지역변수
void SimpleFunc (void){
static int num = 10;
}static은 사실 지역변수가 아닌 전역번수에 매우 가깝다.
그런데 보통은 static 지역변수이다라고 이야기 하는데 이거는 사실 선언의 형태를 근거로 이야기 하는 것이고 사실은 지역변수가 아니라 전역변수이다.
다만 전역변수인데 접근의 범위를 제한하기 위해서 static이라는 키워드를 들고 함수 안으로 들어간 것이였다.
그러면 전역변수에다 static선언을 하면 어떤 의미를 가질까?
static int num = 10;
void SimpleFunc(void){
num = 20;
}
....기존에 int num이 그냥 전역변수라면 extern 명령어를 통해서 다른 파일에 접근하는게 가능했었는데 static int num을 통해서 static로 선언해 뒀다면 다른 파일에서 접근할 수가 없다.
결국 static으로 선언된 전역변수는 외부에서 이 변수에 접근하는 것을 막겠다는 의미이다.
그래서 static을 선언한 변수에는 extern을 선언해서 사용할 수 가 없다.
27-2 둘 이상의 파일을 컴파일하는 방법과 static에 대한 고찰
여태까지 사실상 파일을 나누는 방법이라기 보다는 extern 키워드에 대해서 알아봤었다.
이제 실제로 파일을 나워보면서 공부해보도록 하자.
여태 나누었던 세개의 파일을 하나의 프로젝트 안에 담아서 하나의 실행파일을 생성해보는게 목적이였다.
그렇게 하기 전에 다중 파일 컴파일을 해야하는데 이 방법이 두가지가 있다.
- 파일을 먼저 생성해서 코드를 삽입한 다음에 프로젝트에 추가한다.
- 프로젝트에 파일을 추가한 다음에 코드를 삽입한다.
이 방법은 사실 파일이 기존에 존재 했냐 안했냐를 기준으로 나뉘어 있는 것으로 첫번째 방법인 파일을 먼저 생성해서 코드를 삽입한 다음에 프로젝트에 추가한다 라는 것은 기존에 있는 파일을 가져와서 프로젝트에 넣어서 컴파일 하겠다는 의미이고 두번째 방법은 그냥 코드를 하나 하나 쳐서 파일을 생성해서 컴파일 하겠다는 것이다.
존재하는 파일, 프로젝트에 추가하는 방법
소스파일 마우스 오른쪽 버튼 > 추가 > 기존항목
이렇게 소스파일을 선택하면 솔루션 탐색기에 해당파일이 보여야 한다.
화면상에 소스가 보이는게 중요한게 아니라 솔루션 탐색기에 소스파일에 파일이 존재해야 컴파일 대상으로 올라가는 것이다.
프로젝트에 새로운 파일을 추가하는 방법
소스파일 마우스 오른쪽 버튼 > 추가 > 새항목
위 파일 추가 방법은 왜 알려주는지 모를 정도로 이해할 부분이 없다 그냥 파일 추가하는 방법을 알려준다...
함수에도 static 선언을 할 수 있다.
함수를 대상으로도 static 선언을 할 수 있다.
static void MinCnt(void){
cnt--;
}이건 결국 해당 함수는 해당 파일 내에서만 호출 할 수 있도록 하겠다는 의미로 사용된다.
그래서 사람들은 static으로 선언한 변수 혹은 함수는 FILE 접근 범위를 갖는다고 한다(해당 파일에서만 접근이 가능하다).
27-3 헤더파일의 디자인과 활용
헤더파일이 하는일이 뭔지, #include지시자가 어떤 일을 하는지에 대해서 먼저 알아보도록 하자.
#include 지시자와 헤더파일의 의미
#include는 선행처리기에 의해서 처리되는 지시자이다.
선행처리기의 역할은 치환을 하는 역할을 하는데 결국 #include는 어떤 파일의 내용을 #include 코드 위치와 변경한다는 의미이다.
#include <stdio.h>이 코드는 stdio.h라는 헤더파일을 이곳에 치환해주는 기능을 하는 것이다.
#include는 <>의 내부에 헤더명을 작성하는것 외에 ""을 통해서도 삽입이 가능한데
#include "header1.h"
#include "header2.h"이 또한 같은 기능을 한다.
그러면 header1.h와 header2.h가 어떻게 되어 있는지 확인해보면
//header1.h
{
puts("Hello, world!");
//header2.h
return 0;
}이 두 파일을 보면 말도 안되는 문법으로 작성되어 있는 파일임을 알 수 있는데 이게 컴파일이 되겠냐고 생각하면 당연히 이 파일들은 컴파일이 될수가 없다.
그러나 헤더파일들은 컴파일의 대상이 아니기 때문에 상관이 없다.
헤더 파일이 컴파일이 되는게 아니라 이 파일이 #include 지시자를 통해서 소스코드의 일부가 되고 나서 그 소스코드가 컴파일이 되는 것이기 때문에 문제가 없다.
그렇게 나오는 main.c의 소스파일의 내용은
#include <stdio.h>
int main(void)
#include "header1.h"
#include "header2.h"일 텐데 이 소스코드가 선행처리기에 의해서 만들어지는 소스는
#include <stdio.h>
int main(void)
{
puts("Hello, world!");
return 0;
}이 된다(<stdio.h>는 파일의 내용이 매우 많고 현재는 궂이 보여주는 목적에 부합하지 않기에 그냥 뒀음)
이렇게 include가 선행처리기에 의해 처리가 되면 코드에 문제가 없다.
그런데 이렇게 만드는게 가능하다고 해서 아무렇게나 넣어서 만들어주면 안된다.
여기선 그냥 단순하게 #include의 기능을 확인하기 위한 예제라고 보면 된다.
헤더파일을 include 하는 두 가지 방법
헤더파일을 include하는 방법은 표준 헤더파일과 사용자 정의 헤더파일이냐에 따라 사용하는 방법이 다르다
# 표준 헤더 파일을 사용하는 include방법
#include <헤더파일의 이름>
이 방법을 사용할때는 표준 헤더파일이 저장된 디렉터리에서 헤더파일을 찾아서 포함시킨다.
# 사용자 지정 헤더파일을 사용하는 include 방법
#include "헤더파일의 이름"이 방법을 사용할때는 이 코드를 갖고 있는 소스파일이 저장된 디렉터리에서 헤더파일을 찾는다.
왜 이렇게 방식을 구분했을까?
보통은 컴파일러(사실은 통합개발환경이라고 이야기 하는게 맞음)가 각자의 컴파일러 별로 다르게 표준 헤더파일을 특정위치에 존재하게끔 만들어져서 프로젝트가 생성이 되는데 그 헤더파일의 위치는 그 컴파일러(통합개발환경)가 이미 알고 있다.
그리고 그 위치에서 찾으라는 의미로 사용되는 것이 바로 <>인 것이다.
그래서
#include <stdio.h>의 의미는 내가 사용하고 있는 컴파일러가 갖고 있는 표준 헤더파일을 담고 있는 그 디렉터리 위치에 존재하는 stdio.h파일을 가져와서 여기 소스파일에 include시켜라 라는 의미로 사용되는 것이다.
그렇기에 사용자가 정의한 헤더파일을 사용하고자 할때에는 <>를 통해서 사용하게 되면 파일을 찾지 못한다.
그래서 ""를 사용해서 파일을 찾아 오게 되는데 이때는 위에서 말했듯이 소스파일이 존재하는 그 장소에서 찾아오게 된다.
이때 이전에 fopen을 사용할때 첫번째 인자로 전달하는 파일을 그냥 파일명만 넣고 실행하면 "현재디렉터리"라는 곳에서 파일을 찾아오게 된다고 했는데 ""을 통해서 헤더파일을 가져올때에도 동일한 현재디렉터리에서 헤더파일을 가져오게 된다.
그리고 이 때 현재 디렉터리라는 것은 고정되어 있는 위치가 아니라 변경이 가능하다는 점까지만 알고 있자.
절대경로의 지정과 그에 따른 단점
먼저 헤더 파일을 사용자가 생성한 헤더파일을 사용할 때는 경로를 사용자가 직접 명시해서 찾아올 수 있다.
#include "C:\Users\Admin\C\helloC.h" // --> Windows의 절대경로 지정방식
#include "/Users/Admin/C/hello.h" // --> Linux의 절대경로 지정방식위에서 사용한 경로의 방식은 절대 경로라는 방식으로 해당 파일의 위치가 변경되지 않을 상황에서 사용하는 방법이다.
절대경로로 지정하면 프로그램의 소스파일과 헤더파일을 임의의 위치로 이동시킬 수 없다(동일 운영체제를 기반으로 하더라도).
그리고 운영체제가 달라지면 디렉터리의 구조가 달라지기 때문에 경로지정에 대한 부분을 전부 수정해줘야 한다.
상대경로의 지정
상대 경로라는 것은 말 그대로 지금 코드를 실행시키는 소스파일의 위치를 기준으로 파일을 찾는 방법이다.
#include "header.h"아주 대표적으로 위 코드가 상대경로의 예시이다.
이렇게 선언해두면 이 소스를 담고 있는 소스파일을 기준으로 동 폴더에 존재하는 header.h를 찾아오겠다는 의미가 된다
#include "Release\header0.h"그러면 이 경우는 현재 소스파일이 있는 디렉터리 안에 있는 Release라는 폴더 내부에 있는 header0.h파일을 찾아 include해라 라는 의미가 된다.
#include "..\Users\Admin\C\hello.h"라면 현재 소스파일이 있는 디렉터리의 상위에 있는 디렉터리 내부에 있는 Users라는 디렉터리 내부에 있는 Admin 디렉터리 내부에 있는 C 디렉터리 내부에 있는 hello.h를 찾아서 include하라는 의미이다.
이런 형태로 헤더파일 경로를 명시하면 프로그램의 소스코드가 저장되어 있는 디렉터리를 통째로 이동한다면 어디서든 컴파일 및 실행이 가능해진다.
우리는 프로그램을 개발한 이후에 다수의 사람에게 배포하게 될것이기 때문에 모든 사람의 환경에서 사용이 가능하도록하게 하려면 절대경로가 아니라 상대경로로 지정해줘야만 헤더파일을 찾아올 수 있기 때문이다.
헤더파일에 무엇을 담아야 할까?
우리는 헤더파일안에 무엇을 담아야할지 모른다면 헤더파일을 만들기가 어려울 것이다.
파일을 나눠서 프로그램을 개발하는게 일반적이라고 했었는데 파일을 나눴음에도 불구하고 헤더파일을 생성하지 않았다면 문제가 있다는 것이다.
그렇다면 헤더파일 안에는 무엇을 담아야할까
가이드를 하나 제시해보자면, extern선언은 헤더파일에 넣어주자라는 것이다.
무조건은 아니지만 대부분의 extern선언은 헤더파일안에 들어가 주는게 좋다.
그 이유는 하나의 소스파일 내부에 매우 많은 함수와 변수들이 존재하고 이게 다른 파일들에게 다수 사용되는 경우는 다수의 파일에 그 소스파일에 대한 extern 선언을 추가해줘야한다.
이건 상당히 번거로운 일이고 양에 따라서는 불가능에 가까울수도 있는 매우 큰 작업들이 된다.
그렇다면 헤더파일을 하나 선언해서 소스파일에 있는 함수의 extern선언을 모두 헤더파일에 담아주게 된다면 이 소스파일에 있는 함수를 사용하는 다수의 파일에서 헤더 하나만 include해주면 불필요하게 사용하는 함수를 판단해가면서 extern선언을 해줄 필요가 없게 된다.
그런데 모든 파일에 소스파일에 있는 모든 extern 선언이 들어가면 함수 기능을 많아야 3-4개만 쓰는 소스파일의 경우는 코드가 길어지니 손해가 아닌가 생각할 수 도 있다.
그런데 extern선언은 사실 아무리 많이 선언해도 실행파일의 크기가 커진다거나 성능에 영향을 주지 않는다.
그 이유는 extern선언은 컴파일러가 컴파일을 할때 정보제공의 목적으로 작성되는 것이기 때문에 컴파일러만 인지하고 나서 실행파일의 크기를 증가 혹은 성능에 영향을 주지않는다.
이제 예제를 통해서 소스파일을 나누는 기준, 헤더파일을 나누는 기준 및 정의의 형태를 확인해보자.
다음에 나올 예제는 basicArith.h, basicArith.c, areaArith.h, areaArith.c, roundArith.h, roundArith.c, main.c라는 7개의 파일을 갖고 있고 이를 통해 위에 말한 기준들을 알아보도록 하자.
헤더파일과 소스파일의 포함관계
예제 소스파일과 헤더파일의 구성 및 내용
- basicArith.h, basicArith.c ==> 수학과 관련된 기본적인 연산(사칙연산)의 함수의 정의 및 선언
- areaArith.h, areaArith.c ==> 넓이계산과 관련된 함수의 정의 및 선언
- roundArith.h, roundArith.c ==> 둘레계산과 관련된 함수의 정의 및 선언
- main.c
여기서 areaArith.c의 경우는 넓이 계산을 해야하기 때문에 수학의 기본적인 연산을 해야하기 때문에 basicArith.c에 있는 함수를 사용해야만 한다.
동일하게 roundArith.c의 경우도 계산이 필요하기 때문에 basicArith.c가 필요하다.
보면 각 소스파일 하나에 헤더파일 하나가 존재하는데, 소스파일 하나에 그러면 헤더파일은 하나가 존재하면 되냐고 한다면 그렇진 않다.
현재 소스파일의 기능을 보면 어떤 기능을 제공하고자 하는 함수들이 모여 있는 파일임을 알 수 있는데 이 파일은 결국 외부에 어떤 누군가에 의해서 함수들이 가져다 쓰이기 위해서 만들어져있기에 해당 파일에 존재하는 함수들을 extern선언 해서 각 하나씩 갖고 있다면 다른 소스파일에서 가져다 쓰기가 매우 편해지지 않겠는가?
그렇기 때문에 소스파일의 기능과 상황에 맞게 헤더파일은 선언이 되기 마련이나 해당 소스파일의 경우는 각 하나씩 존재하는게 이상적이라고 생각한것으로 보인다.
아무튼, areaArith.c와 roundArith.c는 basicArith.c의 기능을 사용하기 위해서 해당 파일의 기능을 모두 갖고 있는 basicArith.h 헤더 파일을 가져와서 include하도록 하고, main에서는 이렇게 만들어진 areaArith.c와 roundArith.c를 통해서 무엇인가를 실행시킬 코드를 작성시킬 것이기 때문에 각 파일의 기능을 외부에서 사용 가능하도록 만들어준 areaArith.h와 roundArith.h 헤더파일을 가져와서 include 해줄 것이다.

이렇게 되면 컴파일 이후에 링커에 의해서 하나로 묶여서 실행파일로 만들어 진다.
basicArith.h & basicArith.c
#basicArith.c
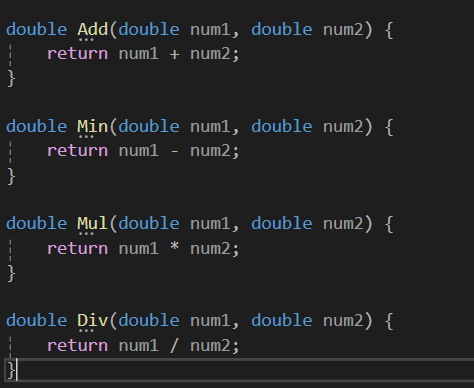
#basicArith.h

먼저 메크로를 사용하는데 이 메크로의 정의는 파일 단위로 유효하다.
그렇기에 PI와 같은 상수의 선언은 헤더파일에 정의하고, 이를 필요로 하는 모든 소스파일에 PI가 선언된 헤더파일을 포함하는 형태로 구성한다.
이렇게 해두면 파일마다 이 헤더파일이 include 되면 그 파일 내부에서 매크로로써 사용되어 질것이다.
areaArith.h & areaArith.c
#areaArith.c

여기선 위에서 말했듯이 기본적인 수학적인 연산함수를 사용하기 위해서 basicArith의 함수들이 필요하기에 함수들에 대한 extern 선언이 들어 있는 basicArith헤더 파일을 include 해준다.
그리고 그 안에 매크로로 선언되어 있는 전역 변수 PI 또한 사용이 가능해진다.
#areaArith.h

roundArith.h & roundArith.c
roundArith.c

roundArith에서 또한 기본적인 수학적인 연산함수를 사용하기 위해서 basicArith의 함수들이 필요하기에 함수들에 대한 extern 선언이 들어 있는 basicArith헤더 파일을 include 해준다.
roundArith.h

main.c

위 areaArith와 roundArith를 main에 include 시켜주면 해당 함수를 사용해서 원하는 내용을 출력할 수 있다.

구조체의 정의는 어디에
구조체의 정의도 파일단위로만 유효하기 때문에 필요하다면 동일한 구조체의 정의를 소스마다 추가시켜야한다.
그렇기에 구조체의 정의 또한 헤더파일에 작성해두고 필요하다면 include 해서 사용하는것이 좋다.
헤더파일의 중복 삽입 문제
헤더 파일을 직간접적으로 두 번 이상 포함하는 것 자체는 문제가 아닌데 두 번 이상 포함시킨 헤더의 내용에 따라서 문제가 될 수 도 있다.
일반적으로 선언은 두 번 이상 포함시켜도 문제가 되지 않으나 정의의 경우는 두번 이상 포함시키게 되면 문제가 된다.
이 중복삽입에 대한 문제점을 해결 하기 위해서 사용할 수 있는 건 #ifndef 매크로가 있다.
#ifndef __STDIV2_H__
#define __STDIV2_H__
typedef struct div{
int quotient; // 몫
int remainder; // 나머지
} Div;
#endif이런 방식으로 하면 해결이 될 수 도 있다.
'Programming Language > C' 카테고리의 다른 글
| 열혈 C - Chapter 26. 매크로와 선행처리기 (0) | 2024.11.15 |
|---|---|
| 열혈 C - Chapter 25. 메모리 관리와 메모리의 동적 할당 (3) | 2024.11.15 |
| 열혈 C - Chapter 24 파일 입출력 (0) | 2024.11.03 |
| 열혈 C - Chapter 23 구조체와 사용자 정의 자료형2 (0) | 2024.10.31 |
| 열혈 C - Chapter 22 구조체와 사용자 정의 자료형1 (0) | 2024.10.28 |