2024. 11. 18. 16:34ㆍProgramming Language/C++
01-1. printf와 scanf를 대신하는 입출력 방식
C++ 버전의 Hello World 출력 프로그램
//예제를 통해 확인할 사실
//헤더 파일의 구성
#include <iostream>
//출력의 기본 구성
std:cout<<'출력대상1'<<'출력대상2'<<'출력대상3';
//개행의 진행
std::endl //을 출력하면 개행이 이뤄진다.
또한 C언어의 경우는 출력 대상에 따라 서식 지정을 다르게 해서 출력 했으나(%d, %g, %f) C++에서는 사용하지 않아도 된다.


scanf를 대신하는 데이터의 입력
//예제를 통해서 확인할 사실 몇가지
//입력의 기본 구성
std::cin>>'변수'
//변수의 선언위치
//함수의 중간 부분에서도 변수의 선언이 가능하다
우선 C++의 경우는 변수의 선언 위치에 제한을 두지 않는다.(C의 경우는 상단에 선언했어야 했음, C99 버전 이후부터는 이게 문제가 없음, C89, C90은 불가능함)
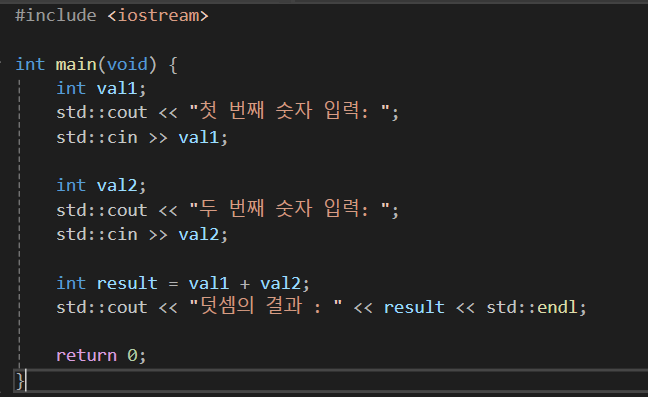
이렇게 변수를 아무데서나 선언해도 문제가 없다.
scanf처럼 입력을 받는 경우에는 화살표의 방향이 >>로 변수를 향하고 있다고 생각하고 printf처럼 출력을 하는 경우에는 << 으로 해당 내용이 out 된다고 생각하자.
그래서 이 결과는

와 같이 출력된다.
C++의 지역변수 선언

다수의 입력을 받기 위해서는

변수를 이와 같이 다수를 분리해서 나열해주면 된다.
std::cin을 통해 입력되는 데이터는 공백(스페이스바, 탭, 엔터)을 통해 구분되어 저장된다.
C++의 경우는 지역변수를 for문의 조건절 내부에서 선언 하는 것도 가능하다.
(이 또한 C언어의 경우는 89, 90버전에선 안되었으나 99버전부터 가능해졌다)

최종적으로 코드의 결과는

와 같이 출력된다.
배열 기반의 문자열 입출력
문자열의 입력방식도 다른 데이터의 입력방식과 크게 차이나진 않는다.


01-2. 함수 오버로딩(Function Overloading)
함수 오버로딩
C++은 함수 호출 시 함수의 이름과 전달 되는 인자의 정보를 동시에 참조하여 호출할 함수를 결정한다.
그렇기에 함수에 매개변수 선언이 다르다면 동일한 이름의 함수를 정의하는 것이 가능하다.
int OverFunc (int num){
num++
return num;
}
int OverFunc (int a, int b){
return a + b;
}
int main(void){
OverFunc(20); // ==> OverFunc(int num)을 호출
OverFunc(30, 40); // ==> OverFunc(int a, int b)을 호출
return 0;
}이런 형태를 함수 오버로딩이라고 한다
함수의 오버로딩이 되는 케이스를 보자면
1. 매개변수의 자료형이 다른 경우
int OverFunc(int num){....};
int OverFunc(char ch){....};
2. 매개변수의 수가 다른경우
int OverFunc(int num){....};
int OverFunc(int num1, int num2){....};
* 반환형의 차이는 함수 오버로딩의 조건이 될 수 없다
void OverFunc(int num){....};
int OverFunc(int num){....};01-3. 매개변수의 디폴트 값(Default Value)
매개변수에 설정하는 '디폴트 값'의 의미
매개변수에 디폴트 값을 설정하는 방법은
int DefaultVal(int num = 12){
return num + 1;
}와 같이 설정할 수 있다.
이렇게 디폴트 값을 설정한 함수의 경우는 전달인자를 전달하지 않을때 매개변수의 값을 디폴트값으로 전달된걸로 간주한다.
그렇기에 위 함수에 아무것도 전달 하지 않는 경우는
DefaultVal();
↓
DefaultVal(12);로 인식한다.
디폴트 값은 함수의 선언에만 위치한다
함수의 선언을 별도로 둘 때에는 디폴트 값의 선언을 함수의 선언부에 위치시켜야 한다.

이건 컴파일러의 컴파일 특성때문이다.
컴파일러는 함수의 디폴트 값의 지정여부를 알아야 함수의 호출 문장을 적절히 컴파일 할 수 있기 때문이다.
# 추가적으로 선언부에 디폴트 값을 넣지 않고 정의부에 디폴트 값을 넣는 경우를 보면

이렇게 선언 하는 경우는 전달인자를 정확하게 전달하지 않으면 오류를 뱉어낸다.
저 함수의 실행 시점에는 함수에 대한 정보를 선언부만을 갖고 할 수 있기에 디폴트 값에 대한 정보를 알지 못한다.
의미는 없지만 만약

이런식으로 실제 함수를 실행하는 시점 이전에 선언부, 정의부가 모두 존재한다면 디폴트 값을 인식해서 값을 만들어낸다.

결론적으로 이 선언부를 의미 있게 사용하는 이유는 함수가 나오기 전에 함수를 실행하고자 할때 사용하는 것이기 때문에 이 선언부에 디폴트 값을 설정해줘야만 함수에 디폴트 값을 설정할 수 있다고 이해하자.
부분적 디폴트 값 설정
함수의 매개변수에 디폴트 값을 설정할때 무조건 모든 매개변수에 디폴트 값을 설정해줘야만 하는 것은 아니다.
원한다면 매개변수의 일부만 디폴트 값을 지정하고 채워지지 않은 매개변수에만 인자를 전달하는 것이 가능하다.
int PartDefault(int num1, int num2 = 5, int num3 = 10){....};
PartDefault(10); //===> PartFunc(10, 4, 10);
PartDefault(5, 20); //===> PartFunc(5, 20, 10);
이때 전달되는 인자는 왼쪽 부터 채워지기 때문에 디폴트 값은 오른쪽 부터 설정해줘야 한다.
만일 디폴트 값을 왼쪽 부터 채워서 부분 디폴트 값을 설정한다면 컴파일 에러를 발생시킨다.


이때는 전달인자를 모두 전달하더라도

에러를 발생시킨다.
01-4. 인라인(inline) 함수
매크로 함수의 장점과 함수의 inline 선언
매크로 함수를 사용하면 함수가 인라인화 되어 성능 향상을 만들 수 있다.
그러나 함수의 정의방식이 일반 함수에 비해 복잡하기에 한계가 있다.
이 때 대안으로 선택할 수 있는 키워드는 inline 키워드이다.

인라인 키워드를 사용할때는 그냥 함수를 생성하듯 생성하면 된다.
inline의 선언은 컴파일러에 의해 처리되기에 컴파일러가 함수의 인라인화를 결정한다.
inline이 선언되어도 인라인 처리 되지 않을 수 도 있고, inline 선언 없이도 인라인 처리가 될 수 도 있다.
그냥 inline은 단순하게 컴파일러한테 이런 함수는 인라인화 시키는게 좋지 않겠냐고 제안하는 것과 같다고 보면 된다.
그렇기에 함수가 너무 크거나 복잡한 경우, 재귀함수인 경우에는 인라인화 되지 않는다.
그렇기에 inline을 썼다고 무조건 인라인화 될것이라고 생각하면 안된다.
인라인 함수에는 없는 메크로 함수만의 장점
매크로 함수의 경우는 전달 인자가 자료형에 묶이지 않기 때문에 다양한 타입을 그냥 사용할 수 있다.
#define SQUARE(X) ((X)*(X))
std::cout << SQUARE(12);
std::cout << SQUARE(3.15);
그러나 inline 선언된 함수는 결국 매개변수에 타입이 지정되기 때문에 다양한 타입의 변수를 받기 위해서는 타입별로 오버로딩 되어야만 한다.
추후에 탬플릿을 사용해서 inline함수를 자료형에 독립적으로 선언하는 방법을 배우기 전까진...
01-5. 이름공간(namespace)에 대한 소개
이름공간의 필요성에 대해서 먼저 알아보자.
만약 프로그램을 개발한다고 가정을 해보자.
이 프로그램의 개발을 위해서 라이브러리가 필요해서 A시, B사, C사의 라이브러리를 사용해야하는 상황이다.그런데 A사도 B사도 C사도 Func() 라는 함수가 존재하고 내가 구현한 하나의 소스코드 내에서 모든 회사의 Func() 함수를 호출해야 한다면 구분이 불가능하다.
우리가 갖고 있는 C언어의 기본적인 지식만 갖고서는 쉽게 구분할 수가 없다.
그러면 어떻게 구분해줘야 할까?
글로 작성해보자면 A사의 Func(), B사의 Func(), C사의 Func() 라고 명시할 수 있다면 직관적이고 구분이 쉽지 않겠는가?
이렇게 이름의 충돌, 이름충돌이라고 하는 이 상황을 막을 수 있을것 같다고 생각이든다.
이런 상황에서 A사의 Func(), B사의 Func(), C사의 Func() 라고 명시해주는 것이 이름공간이다.
A사, B사, C사의 이름공간을 선언하고 그 내부에 Func() 각각 존재하는 것이다.
그리고 우리는 프로그램 상에서 단순히 Func()만 호출하는게 아니라 어떤 이름공간에 존재하는 Func()를 호출하겠다, C에 있는 Func()를 호출하겠다 와 같이 함수나 변수를 특정 이름으로 그룹화 시키는 기능이 이름공간이다.
결론적으로 이름 충돌을 막기 위해서 사용하는 것이 이름 공간이다.
이름공간의 기본원리
보통 우리는 함수를 정의하기 위해서
void SimpleFunc(void){
std::cout << "SimpleFunc() "<<std::endl;
}와 같이 선언을 하는데 이름 공간을 사용해서 구역을 나눠서 동일한 이름의 함수를 선언한다면

와 같이 사용할 수 있다.
여기서

이 부분은 BestComImpl라는 이름공간에 존재하는 SimpleFunc()를 호출하겠다는 의미로 사용되는 코드로 namespace와 함수 사이에 존재하는 ::연산자는 범위지정 연산자로 어디에 있는 어떤 함수를 선언할것인지를 연결해주는 연산자이다.
namespace::functionNM //==> namespace공간에 있는 functionNM을 호출한다
이렇게 이름공간. namespace를 달리하면 동일한 이름의 함수 혹은 변수를 선언하는 것도 가능하다.
하나 첨언 하자면 라이브러리를 개발하는 각각의 회사는 서로 상의를 하고 함수를 만들지는 않는다.
그렇기 때문에 당연히 함수명이 겹칠수도 있고 당연히 같은 공간에서 같은 이름의 함수를 사용해야할 수도 있다.
Never Say Never이기 때문에.. 그렇기에 이런 사용법이 생겼다는거..!
이름공간 기반의 함수 선언과 정의의 분리

이렇게 선언과 정의를 분리할 수 있다.
함수를 선언하기 위해서는 반드시 이름공간에 넣어줘야만 하고 위에서 namespace를 생성하고 함수를 그 내부에 선언했다면 실제 함수를 정의할때는 함수명 앞에 어떤 namespace에 존재하는 것인지를 반환타입과 함수명 사이에 범위지정 연산자를 붙여서 넣어주면서 정의하면 된다.
// 선언부
namespace namespace명{
반환타입 함수명(매개변수);
}
ex)
name space TestSpace {
void TestFunc(void);
}
// 정의부
반환타입 namespace명::함수명(매개변수){
함수 내용;
}
ex)
void TestSpace::TestFunc(void){
std::cout << "테스트 코드" << std:endl;
}
동일한 이름 공간 내에서의 함수 호출
namespace를 선언할때 하나의 영역으로 생성해서 그 안에 모두 넣어야하는 것은 아니고 동일한 namespace가 선언되었다면 같은 공간으로 인식해서 서로의 공간을 공유한다.
namespace TestSpace {
void SimpleFunc(void);
}
namespace TestSpace {
void GoodFunc(void);
}위에서 설명했듯이 이렇게 두개가 선언된다면
namespace TestSpace {
void SimpleFunc(void);
void GoodFunc(void);
}이거와 동일하게 인식한다.
void TestSpace::SimpleFun(void){
std::cout << "Test를 위한 함수" << std:endl;
GoodFunc(); // 동일한 이름공간에 있는 GoodFunc()를 호출
RealSpace::GoodFunc(); // 다른 이름공간에 있는 GoodFunc()를 호출
}
void TestSpace::GoodFunc(void){
std::cout << "So Goooood!" << std:endl;
}그리고 하나 알아둬야 할점은 만약 namespace를 명시하지 않고 namespace에 있는 함수에서 namespace에 있는 함수를 사용할 경우 같은 namespace안에서 호출할 함수를 찾게 되기에 SimpleFunc함수 내부에서 GoodFunc를 namespace를 명시하지 않고 직접 호출하는 것이 가능하다.
이름공간의 중첩
이름 공간은 중첩이 가능하고 그렇기에 계층적 구조를 갖게끔 이름공간을 구성할 수 도 있다.
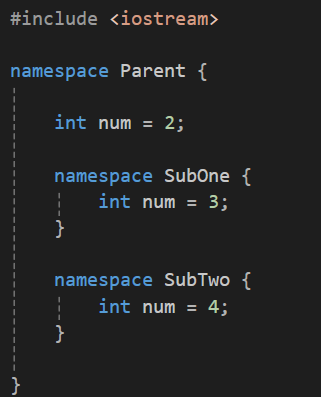
여기서 각각의 요소를 구분하자면
- namespace Parent 안에 존재하는 num
- namespace Parent 안에 존재하는 SubOne
- namespace Parent 안에 존재하는 SubOne안에 존재하는 num
- namespace Parent 안에 존재하는 SubTwo
- namespace Parent 안에 존재하는 SubTwo안에 존재하는 num
로 나눌 수 있고 각각에 접근하는 방식은
//namespace Parent 안에 존재하는 num
Parent::num
//namespace Parent 안에 존재하는 SubOne안에 존재하는 num
Parent::SubOne::num
//namespace Parent 안에 존재하는 SubTwo안에 존재하는 num
Parent::SubTwo::num와 같이 사용하면 된다.
std::cout, std::cin, std::endl
그러면 이 위에 나열한 이 함수들은 어떤 의미가 있을까
이 함수들은 <iostream>에 선언되어 있는 함수로 이름공간 std안에 선언되어 있는 함수이다.
- std:cout ----> 이름공간 std안에 선언된 cout
- std::cin ----> 이름공간 std안에 선언된 cin
- std::endl ----> 이름공간 std안에 선언된 endl
이렇게 이름충돌을 막기위해서, C++표준에서 제공하는 다양한 요소들은 이름공간 std안에 선언되어 있다
namespace std {
cout . . . .
cin . . . .
endl . . . .
}
using을 이용한 이름공간의 명시
using이란 키워드는 추가적인 선언을 생략하면서 함수를 이용할 수 있는 키워드로

이렇게 사용한다.
자세히 보면 상단에 using 키워드를 통해서
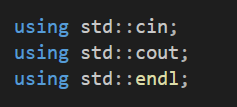
이제부터 cin, cout, endl은 std::cin, std::cout, std::endl을 의미하도록 사용하겠다라고 선언하는 선언부이다.
그렇기에 main함수 내부 코드를 보면

std::를 사용하지 않고 함수에 바로 접근할 수 있는 모습을 볼 수 있다.

using namespace명::내부요소
// ===> namespace명에 있는 내부요소는 이제 namespace명 선언 없이 사용해도 괜찮다
또한
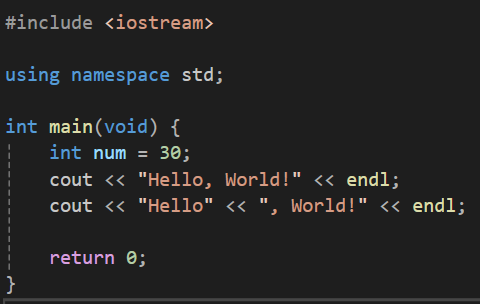
이렇게 선언하면 이제부터 std namespace에 존재하는 함수들은 std라는 이름공간의 선언 없이 접근하겠다는 선언이 된다.

using namespace namespace명;
// ===> namespace명에 있는 모든 요소는 이제 namespace명시 없이 사용할 수 있다
그런데 잘 생각해봐야 할것은 이렇게 무분별하게 사용하다 보면 이름공간을 사용하는 의미가 없어질 수 도 있기에 제한적으로 사용할 필요성이 있다.
이름공간의 별칭 지정과 전역변수의 접근

와 같은 코드가 있을때
namespace ABC=AAA::BBB::CCC;
와 같이 AAA::BBB::CCC명시에 대해서 별칭 ABC를 붙이면
ABC::num1 = 10;
ABC::num2 = 20;
와 같이 하나의 별칭으로 이름공간의 선언을 대신할 수 있다.
추가로 범위지정 연산자는 지역변수가 아닌 전역변수의 접근에도 사용이 가능하다.
int val - 100; // 전역변수
int SimpleFunc(void){
int val = 20; // 지역변수
val += 3; // 지역변수 val에 3을 추가
::val += 7; // 전역변수 val에 7을 추가
}
▼ #::와 namespace:: 의 차이
::를 이름공간명을 붙이지 않고 그냥 ::변수명 과 같이 사용하면 전역범위에 있는 변수를 참조하게 된다.
이는 현재 이름공간 혹은 함수에서 정의된 변수와 전역변수의 이름이 충돌할 경우(동일할 경우), 전역 변수를 명시적으로 참조하는 방법이다.
그에 반면 namespace명::변수명은 어떤 namespace에 있는 변수인지를 한정지어 참조할 수 있는 방법이다.
'Programming Language > C++' 카테고리의 다른 글
| 열혈 C++ - Chapter 04. 클래스의 완성 (2) | 2024.11.24 |
|---|---|
| 열혈 C++ - Chapter 03. 클래스의 기본 (0) | 2024.11.19 |
| 열혈 C++ - Chapter 02. C언어 기반의 C++ 2 (0) | 2024.11.19 |