2024. 11. 24. 14:45ㆍProgramming Language/C++
Chapter 04-1. 정보은닉
프로그래밍은 객체간의 관계를 구성해주는 것이 중요하다.
그런데 객체를 정의함에 있어서 모두 정보은닉, 캡슐화가 되어있어야한다.
여기서 정보은닉은 멤버변수(정보)를 감추겠다(은닉하겠다.)
해당 클래스가 아닌 다른 영역, 다른 클래스에서 접근이 불가능하도록 하겠다는 것이 바로 정보 은닉인것이다.
그러면 정보 은닉은 모두 쉽게 할 수있는 개념이다.
물론 이렇게 정보에 접근만 못하게 한다고 정보를 은닉했다고 할 수 있는 것은 아니다.
접근을 막았으니까 다른 경로로 내가 원하는 방향으로 접근할 수 있도록 길을 만들어 줘야만한다.
아예 접근을 못하게 하면 클래스 자체를 선언하는 의미가 없기 때문에 어떤 방법으로든 접근은 할 수 있어야 한다.
그러면 캡슐화는 무엇일까.
캡슐화를 했다 라는 것은 어떤 클래스안에 그 클래스에 관련된 내용을 그 안에 다 잘 담아뒀다는 의미이다.
어떤 클래스 안에 있는 기능 혹은 정보들을 해당 클래스가 아닌 다른 클래스에 조금 심어 놨다 라고 한다면 이건 캡슐화가 무너진 것이다.
하나의 클래스는 하나의 목적을 위해서 정의가 된다.
이 목적을 완성하기 위한 모든 변수와 모든 함수가 해당 클래스 안에 모두 담기는 것이 캡슐화이다.
Car 클래스를 선언 한다면 Car와 관련된 모든 내용을 넣으면 되고 Person 클래스를 선언한다면 Person에 관련된 내용 모두 넣으면 되지 이게 뭐가 어렵냐 라고 생각할 수도 있다.
이게 어려운 이유는 Car와 Person만 봐도 만약 자동차 운전자 보험이다. 라고 생각한다면 이건 Car에 넣어야 할까,Person에 넣어야 할까?
사실 이건 상황에(구현하고자 하는 프로그램에) 따라 달라질 수 있기 때문에 정답이란게 그때 그때 달라질 수 있다.
캡슐화라는 것은 결국 관련있는 것을 결정짓는게 정답이 없기 때문에 캡슐화가 매우 어렵다.
프로그래밍을 할때 하나의 클래스가 얼마나 캡슐화가 되어 있는지를 확인하면 프로그래밍 능력을 볼 수 있을 정도이다.
(이건 꾸준히 조금씩 경험과 경력에 의해서 늘어날 수 있는 스킬이라고 본다고 함)
그러면 캡슐화를 왜 잘해야할까
캡슐화를 잘 못하면 하나의 클래스가 일부 기능을 확장하거나 잘못된 기능을 수정하고자 할때 다른 클래스의 변경을 요하게 되는 경우가 많고 이럴때 그 다른 클래스와 연관된 또 다른 클래스들도 변경될 여지가 있기 때문이다.
그래서 캡슐화라는 것은 클래스별로 독립성을 갖게 하고 그로 인해 변경이나 확장에 대응이 가능한 상태로 클래스의 수준을 높이는 것이라고 할 수 있다.
정보은닉의 이해
클래스의 멤버변수에 외부 접근을 허용하면 잘못된 값이 저장되는 문제가 발생할 수 있다.
그렇기에 멤버변수의 외부 접근을 막는데 이를 정보은닉이라고 한다.
정보은닉이 되지 않은 케이스에 대해서 보자면 하나의 그림판을 그려본다고 생각해보자.
그림판의 맨 좌측 상단을 0, 0 의 좌표를 갖고 우측 하단이 100, 100의 좌표를 가진다.

이런 케이스에서 우리가 멤버변수에 들어오기를 바라는 데이터의 형태가 있을 텐데 위와 같이 정보은닉을 하지 않고 선언하는 경우에는 우리가 바라는 형태의 데이터가 아닌 데이터가 들어오는 것을 막을 수 가 없다.
위 클래스들은 메인 함수 내부에서

와 같은 형태로 사용이 될텐데 이렇게 사용된다면

우리가 제한했던 Point의 멤버변수의 범위 0 ~ 100의 이내의 값의 제한과

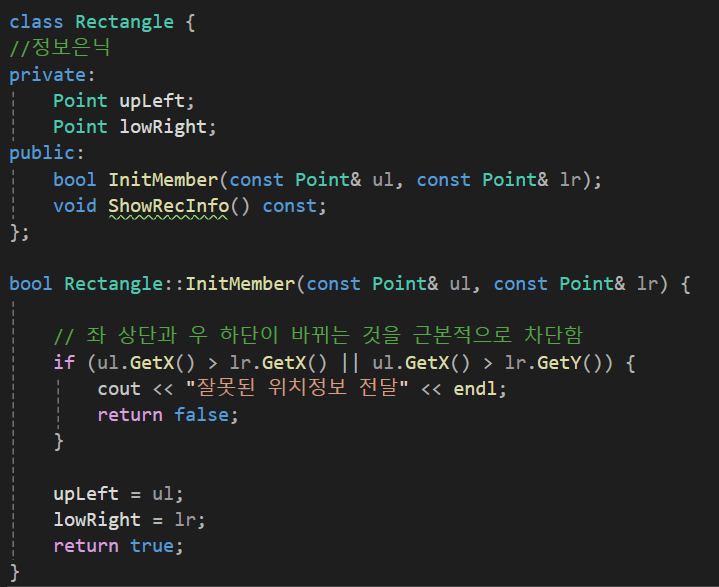
Rectangle에 들어오기를 바라는 좌상방 Point 객체와 우하방의 Point 객체가 뒤바뀐다면

이를 제어할 방법이 없다.
Point 클래스의 정보은닉 결과
이제 Point 클래스부터 정보은닉을 해보자.
정보은닉은 간단하게 접근제한자를 멤버변수에 걸어주면 된다.

그리고 그 클래스의 멤버변수에 접근하는 함수를 별도로 정의해서
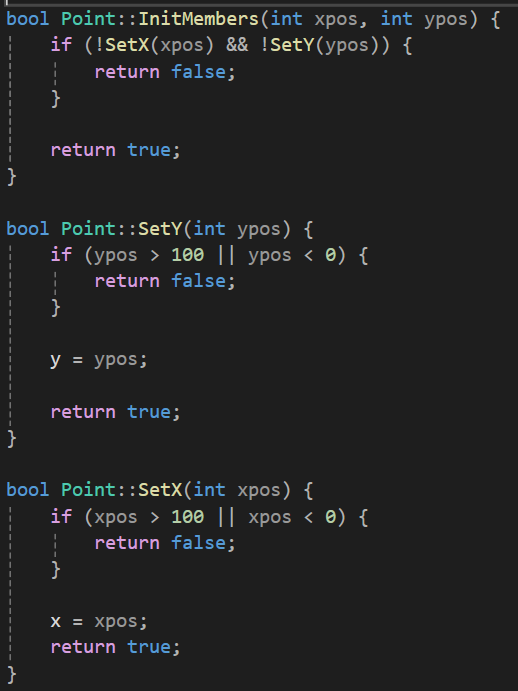
안전한 형태로 멤버변수의 접근을 유도하는 방법이 정보은닉이며 이건 좋은 클래스가 되기 위한 기본 조건이 된다.
Rectangle 클래스의 정보은닉 결과
const 함수
멤버함수의 const 선언
int GetX() const;
int GetY() const;
void ShowRecInfo() const;const 함수 내에서는 동일 클래스에 선언된 멤버변수의 값을 변경하지 못한다.
const함수는 const가 아닌 함수를 호출하지 못한다.
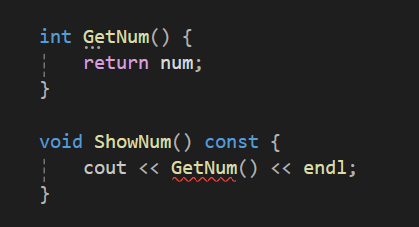
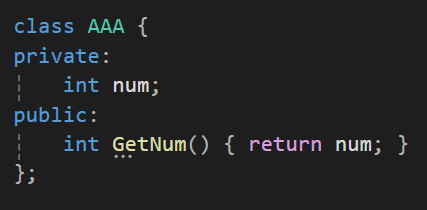
이렇게 에러가 발생한다.
보면 GetNum은 num이라는 멤버변수를 변경하지않는데도 불구하고 ShowNum내부에서 호출된 GetNum함수에는 에러가 발생하고 있다.
이는 const 함수 내에서 const로 선언하지 않은 함수를 호출했기 때문에 에러가 발생하는 것이다.
아니 변경도 안하는데 왜 에러를 띄울까?
이는 GetNum이란 함수는 값을 변경할 수 있는 가능성을 지닌 함수이기 때문이다.
정확하게는 컴파일러가 컴파일 할때 ShowNum 함수 안으로 들어 올때 아 이건 const로 내부에서 멤버변수의 값을 변경시키지 않겠구나 하고 들어와서 GetNum 함수를 만난다.
그러면 컴파일러는 이 GetNum함수의 정의문으로 간다 그리고 그 내부를 보는것이 아니라 아 얘는 GetNum이라는 함수이고 int 값을 반환하는 구나 정도만 정의문에서 확인하고 돌아온다.
즉, 컴파일 할때 이 GetNum안에서 값을 변경하는지 안하는지를 확인하지 않고 되돌아온다.
그렇기 때문에 단순하게

여기만 바라보고 나서 GetNum을 확인하러 가서

이것만 보고 "어? 뭐야 애 const 선언을 안했어? 그럼 뭐야 내부에서 값 변경하겠다는 말이야 뭐야!"라고서 에러를 띄워버린다.
그렇기에 const 함수는 const 함수만 호출할 수 있다.
이것 처럼 하나의 함수에 const를 설정해주면 그거랑 연관되어 있는 많은 기능들에 const가 붙어야한다.
이게 안좋은건 아니고 오히려 프로그램의 안정성을 늘려주기 때문에 좋은 방향이라고 볼 수 있다.
간접적인 멤버의 변경 가능성까지 완전 차단할 수 있다.

const로 상수화 된 객체를 대상으로는 const 멤버함수만 호출이 가능하다.
이 또한 위에서 했던것 처럼 const 참조자의 경우는 그 참조자가 바라보고 있는 값을 변경하지 않겠다는 의미이다.
easy를 통해서 GetNum을 불렀다고 한다면 동일하게 컴파일러가 같은 이유로 에러를 띄운다.
const로 선언된 참조자는 const로 선언한 함수만 허용하겠다는 의미이다.
const를 선언해보면서 const 때문에 안된다고 const를 지우지 말고 한번 const를 여기저기 써가면서 해결해보자.
자주 해봐야 능력이 오른다..!!
const 함수는 객체의 상태를 변경하지 않겠다고 약속하는 특별한 멤버 함수다. 이 함수들은 클래스의 데이터를 읽기만 하고 수정하지 않는다. 함수 선언 끝에 const 키워드를 붙여 정의한다. const 함수의 특징이다
- 멤버 변수 수정 불가: const 함수 내에서는 객체의 멤버 변수 값을 직접 변경할 수 없다.
- 안전성 보장: const 함수는 객체의 상태를 변경하지 않으므로 예측 가능하고 안전한 동작을 보장한다.
- const 객체에서 호출 가능: const로 선언된 객체에서도 const 함수를 호출할 수 있다.
const 함수의 제약사항
- 비 const 함수 호출 불가: const 함수 내에서는 같은 클래스의 비 const 멤버 함수를 호출할 수 없다.
- 멤버 변수 변경 시도 시 컴파일 에러: const 함수 내에서 멤버 변수를 변경하려고 하면 컴파일 오류가 발생한다.
const 함수의 사용 이점
- 코드의 안정성 향상: 객체의 상태 변경을 제한하여 예기치 않은 부작용을 방지한다.
- 가독성 증가: 함수의 의도를 명확히 표현하여 코드 이해도를 높인다.
- 최적화 기회: 컴파일러가 const 함수의 특성을 활용해 최적화를 수행할 수 있다.
const 함수 사용 시 주의사항
- mutable 키워드: mutable로 선언된 멤버 변수는 const 함수 내에서도 수정 가능하다.
- const_cast 사용 주의: const_cast를 통해 const를 제거할 수 있지만, 이는 const의 의도를 해치므로 주의해야 한다.
결론적으로, const 함수는 C++에서 객체의 불변성을 보장하고 코드의 안정성을 높이는 중요한 도구다.
적절히 사용하면 더 안전하고 유지보수가 쉬운 코드를 작성할 수 있다.
Chapter 04-2. 캡슐화
콘택600과 캡슐화
콘택 600이라는 캡슐 감기약이 있고 이걸 클래스로 생성해보자.
이 콘택 600은 코감기약으로 이 코감기약을 클래스로 설계한다고 생각해보자.
먼저 콧물/재채기/코막힘과 관련된 클래스가 있다.
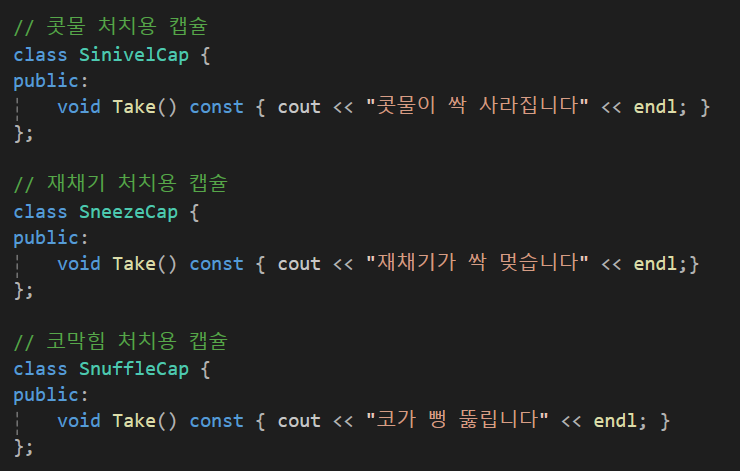
이게 캡슐화가 잘 되어 있는 상황일까?
사실 이 내용만 가지고선 잘 캡슐화가 된 상황인지 안된 상황인지 판단할 수 가 없다.
각각 하나의 클래스이고 하나 하나 자신만의 기능만 갖고 있다고 한다면 잘 캡슐화가 되었다고 할 수 있는데 사실 얘를 다른 관점에서 보면 코감기와 관련된 기능을 모두 하나의 클래스에 넣지 않았기에 캡슐화가 잘 되어 있지 않다고도 말할 수 있다.
이처럼 어떻게 사용할것인지에 대해서 캡슐화가 잘 되었을 수 도, 잘 안 되었을 수 도 있다.
만약 콧물과 재채기와 코막힘이 동시에 동반되지 않고, 약을 복용함에 있어서 쉽게 조합이 가능하다면(약을 콧물약 >> 재채기 >> 코막힘 약의 순서대로 먹어야한다라던가 등의 제한이 있는 경우) 위처럼 만드는 것이 캡슐화를 잘 했다고 할 수 도 있다.
그런데 모두 동반되거나 약을 복용하는 방법이 매우 제한되어 있다면 캡슐화가 전혀 되어 있지 않은 코드가 되는 것이다.
캡슐화된 콘택 600
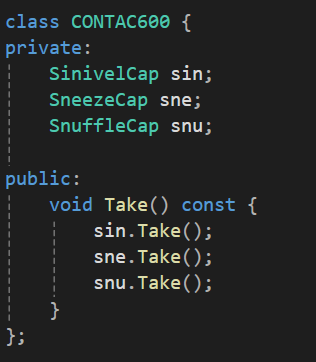
근데 보면 캡슐화는 하나의 클래스에 자신이 갖고 있는 모든걸 넣어둔다고 했었는데 이렇게 관련된 모든것을 채워 넣을 수 있는 방법은 위처럼 다른 클래스들을 맴버변수의 형태로 구성하더라도 이건 캡슐화가 되는 것이다.

즉, 이런 클래스들을 모두 까서 클래스 안에 넣어줘야 하는게 아니라 작은 클래스를 디자인하고 이걸 더 큰 클래스의 캡슐화를 위해서 일부 사용되는 것은 캡슐화에 문제가 안된다는 것이다.
아무튼 이렇게

코감기에 대한 내용을 하나의 클래스에 선언하고 그와 관련된 클래스 또한 복용 순서에 따라 나열 시켜놨다.
이렇게 한번에 정의 한 경우엔

이렇게 선언을 했을때 그냥 CONTAC600에서 Take 하나만 호출해주면 모든 약을 한번에 복용이 가능하다는 것이다.
만약 CONTAC600이 없었다면 SinivelCap, SneezeCap, SnuffleCap을 모두 불러서 Take를 호출하는데 또 복용 순서를 생각해가면서 다 호출해줘야만 했을 것이다.
근데 만약 도중에 복용의 순서가 바뀐다면 ColdPatient class 내부의 소스를 변경해줘야만 한다.
그런데 만약 CONTAC600이 있다면 결국 그 내부에서만 변경해주면 ColdPatient에서는 변경할 내용이 전혀 없게 된다는 것이다.
결론적으로 보자면 감기걸린 환자 입장에서는 약의 복용순서를 외워가면서 약을 하나 하나 복용하는 방법 보다는 하나의 종합 감기약 세트를 먹으면 그 안에서 알아서 순서대로 약을 복용해주는 하나의 약을 먹는게 더 좋다는 것이다.
약의 복용 순서가 바뀌더라도 종합 감기약 세트 내부에서 약을 먹는 순서를 알아서 다시 맞추고 나면 감기 걸린 환자는 그냥 동일하게 약을 먹기만 하면 되는 것이다.
** 캡슐화는 결국엔 자기가 어떻게 구성을 하고자 하고 그 방향대로 만들어 졌다면 그게 캡슐화가 되었다고 볼 수 도 있다.
예를 들어서 비타민을 종합 비타민을 먹는 사람이 있는 반면 비타민 하나 하나 종류별로 따져가면서 챙겨 먹는 사람들도 있다.
이 사람들중 어느 하나가 비타민을 먹는 방법이 정답인지 말할 수 는 없다.
왜냐면 그들도 약을 종합으로 먹는 이유와 목적이 있을 것이고 하나 하나의 비타민을 골라가면서 섭취하는 이유와 목적 또한 다르게 있을 것이기 때문이다.
캡슐화 또한 이와 같이 이유와 목적이 명확하고 타당하다면 또 그게 자신이 목표한 목적에 의미가 있다고 생각한다면 그 목적에 맞게만 만들면 되는 것이라고 생각 된다.
Chapter 04-3. 생성자와 소멸자
생성자
클래스를 배우고 난 후에 그 클래스를 기반으로 객체를 생성하는 가장 기본적인 방법도 확인했었다.
그리고 객체에서 가장 기본적인 내용인 정보은닉과 캡슐화에 대해서도 이야기 했었다.
그런데 아직 객체생성에 대해서 확인하지 않은 내용들이 많다.
변수를 선언한다면 기본적으로
int num;변수를 선언한 다음에 내가 원하는 시점에 변수에 값을
num = 20;초기화하기도 하지만 변수를 선언함과 동시에 초기화를 하기도 한다.
int num = 30;
여태까지 우리는 객체를 선언해서 별도의 함수를 통해서 멤버변수들을 초기화하는 과정을 거쳤었다.
그런데 사실 객체를 선언하는 것은 어떤 가치가 있는 무엇인가가 생성되는 것으로 객체를 생성하고 나중에 필요할때 초기화하는 방식으로 사용하지 않는다.
객체가 생성되었다는 것은 그 객체가 하나의 독립된 값이 생성되었다는 뜻이고, 그렇기에 객체는 생성되면서 적절한 값으로 초기화가 이뤄져야만 한다.
이렇게 객체가 생성될때마다 초기화를 할 수 있도록 만드는 것이 생성자로 이는 함수의 일종이다.
객체의 초기화는 결국 어떻게는 함수를 호출하는 과정이 필요하다.
그러나 기존엔 우리가 명시적으로 함수를 호출해서 값을 넣었다면 생성자는 객체가 호출될때 자동으로 호출되는 함수이다.
소멸자
생성자와 반대 개념을 가진것이 소멸자이다.
소멸자는 객체가 소멸될때 자동으로 호출되는 함수이다.
그럼 소멸자는 왜 필요할까
생성자같은 경우는 생성될때 함수가 자동으로 호출되기에 그 안에서 리소스의 할당이나 기타연산들을 할 수 가 있는데 이런 연산중 일부는 정리가 필요한 경우가 있다.
예를 들어 new 키워드를 통해서 객체 생성을 위한 메모리 공간이 할당 되었다면 이 메모리공간은 객체가 소멸될때 같이 소멸되어야 한다.
그런데 new라는 연산자를 통해서 만들어진 heap area의 메모리 공간은 우리가 따로 delete연산을 해주지 않으면 소멸되지 않는다.
그렇기에 new를 통해 할당된 메모리 공간을 소멸시켜주는 delete연산이 필요한 시점이 객체가 소멸되는 시점이다.
그렇기에 자동으로 호출되는 소멸자라는 함수를 만들어 이렇게 할당되는 메모리공간을 반환하기에 매우 좋은 성능을 가지게 되었다라는 것이다.
그래서 소멸자의 역할은 생성자에서 할당한 메모리공간을 정리하는 것이 가장 큰 의미를 갖는다.
생성자의 이해
클래스의 이름과 동일한 이름의 함수이면서 반환형이 선언되지 않고 실제로 반환하지 않는 함수를 가리켜 생성자라고 한다.

생성자는 초기화시 딱 한번만 호출되기에 멤버변수의 초기화에 사용이 가능하다.
생성자도 함수의 일종이기에 오버로딩이 가능하고 디폴드 값 설정이 가능하다.
생성자를 사용하는 것을 보면

이렇게 사용하는 것을 볼 수 있다.
클래스를 가지고 객체를 생성할때 아래와 같은 방식으로 호출하게 되면
//클래스명 객체명(전달인자);
SimpleClass sc(20);
SimpleClass를 기반으로 sc라는 객체를 생성하는데 20이라는 값을 생성자에게 전달한다.
결국 위에 있는 SimpleClass를 기반으로 보자면
SimpleClass 객체 생성(객체명 sc) -> 생성자 SimpleClass에 30전달 -> 멤버 변수인 num = 30으로 멤버변수 초기화
의 과정이 진행된다.
이 경우에는 steak의 공간에 할당하는 방법이고 동적으로 할당한다면
// 동적할당하는 경우
SimpleClass * ptr = new SimpleClass // 기존 사용방식
SimpleClass * ptr = new SimpleClass(20) // 생성자 사용 동적할당 방식와 같은 방식으로 객체에 초기값을 전달해줘야 한다.
이러면 Heap area에 객체를 생성하면서 객체 안에 num을 20으로 초기화한다.
그러면 만약 생성자를 정의하지 않는다면 어떻게 될까?
생성자를 정의하지 않아도 생성자는 호출된다.
우리가 객체라고 이야기 하려면 메모리 공간에 할당이되고 반드시 생성자는 호출되어야 한다.
생성자의 호출과정을 거치지 않으면 객체라고 할 수 없다.
하나도 생성자를 정의하지 않는다면 컴파일러에 의해서 default 생성자라는 것이 삽입된다.
이 default 생성자는
SimpleClass() {}이런 형태를 띈다.
인자값이 없기에 void 생성자라고도 하며 이 생성자가 하는 일은 아무것도 없다.
그러면 이 디폴트 생성자를 통해서 모든 객체는 한번의 생성자 호출을 거치도록 정의가 되었는데 앞에서 우리가 객체 생성을 어떻게 했냐면
SimpleClass Obj;이렇게 했었는데 이때 어떤 생성자를 호출할지 명시하지 않았는데(()를 통해서 값을 전달하지 않았는데) 이럴 땐 인자값을 받지 않는 void 생성자의 호출이라고 생각해야한다.
그런데 만약 우리가 생성자를 하나 생성했다면(위에 처럼) 그때는 디폴트 생성자를 부르면서 객체를 생성하는 방식이 허용될까?
// 생성한 생성자를 통해 객체를 생성
SimpleClass sc(20);
// 디폴트 생성자를 통해 객체를 생성
SimpleClass sc;불가능하다.
디폴트생성자는 사용자가 해당 클래스에 어떤 생성자도 생성하지 않았을때 만들어주는 것이기 때문에 생성자가 존재한다면 디폴트 생성자를 통해 객체를 생성하는 방식이 불가능하다.
그러면 디폴트 생성자를 통해 객체를 생성하는 방식이 사용 가능하게 하려면 어떻게 해야할까
SimpleClass (){
}
SimpleClass(int n ){
num = n;
}이렇게 우리가 직접 디폴트 생성자를 생성해주면 된다.
이를 보면 하나의 클래스에 동일한 이름, 다른 매개변수 타입인 생성자를 생성 가능한 오버로딩이 가능함을 알 수 있다
결국 생성자도 함수고 오버로딩이 가능하기 때문에 이런 다양한 생성자를 사용한 객체생성이 가능하다고 바꿔 생각해볼 수 있다.
생성자의 함수적 특성
생성자도 함수의 일종이기에 오버로딩이 가능하다.
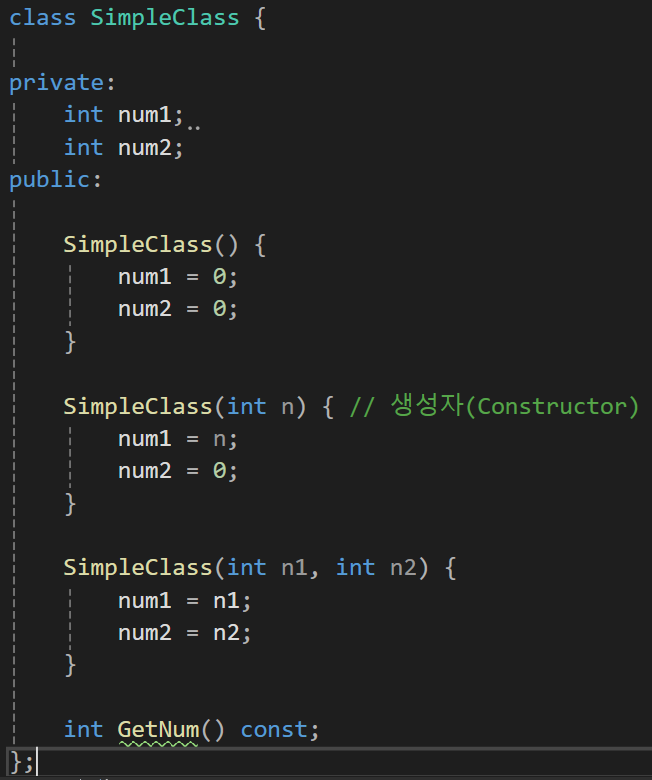
이렇게 3종류의 생성자를 사용한다면
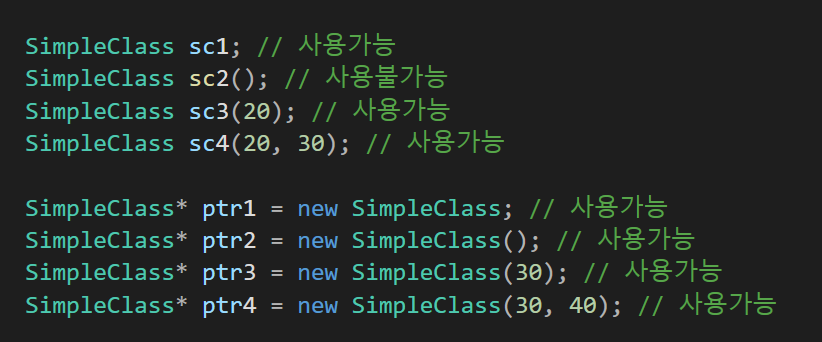
와 같이 사용이 가능하다.
그런데 여기서
SimpleClass * ptr = new SimpleClass(); // 가능
SimpleClass sc(); // 불가능
동적할당된 ptr은 new SimpleClass와 new SimpleClass()가 둘다 디폴트 생성자를 본다는 가정하에 생성이 되는데, SimpleClass sc는 디폴트 생성자를 부르고 SimpleClass sc()는 안되는 이유는 SimpleClass sc() 이게 함수의 원형의 선언과 겹치기 때문이다.
C++은 해당 코드를 함수의 이름이 sc이면서 매개변수는 void이고 return 타입이 SimpleClass인 함수의 선언으로 인식할 수 있기 때문이다 .
그렇기에 저런 형태의 객체 생성은 혼란을 만들지 않게 그냥 불가능하게 막아둔 것이다.
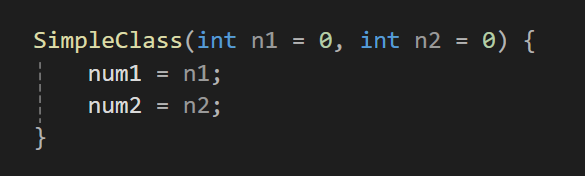
생성자는 함수이기에 매개변수에 디폴트 값의 설정도 가능하다
Point와 Rectangle 클래스에 생성자 적용

포인트 클래스에 xpos와 ypos를 받아 x와 y를 초기화 시키는 생성자가 추가 되었는데

&xpos 참조자가 매개변수로 지정되어 있으면 변수만 받을 수 있으나 const로 선언되어 있기 때문에 변수 및 상수를 모두 받을 수 있는 생성자가 되었다.
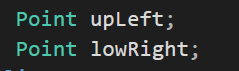
Point 클래스의 경우는 생성자의 추가가 이렇게 어렵지 않았는데 문제는 Rectangle 클래스이다.

Rectangle 클래스의 경우는 Point 형으로 upLeft와 lowRight를 맴버변수로 받고 있다.
Point와 동일하게 두가지 멤버변수를 선언과 동시에 초기화해줄 수 없다.
그렇다면 생성자에서 초기화를 해줘야하는데 조금 더 좋은 방법을 제시할 수 있다.
멤버 변수 안에서 두개의 Point 객체를 생성해서 초기화를 해줘야하는데 중요한 것은 Rectangle이라는 생성자 안에서 별도의 생성과정을 거친다면
만약 Point와 Rectangle 클래스 모두 생성자가 정의가 안되어 있다고 생각 한다면, 둘다 디폴트 생성자를 자동으로 생성해줄것이다.
이때 Rectangle 객체를 생성한다면 메모리 공간을 할당한 다음에 Rectangle 디폴트 생성자가 호출된다.
그러면 객체 생성이 완료 되는데 이 의미는 그 안에 멤버변수인 Point 객체 두개가 각각 메모리 공간에 할당 되었다는 의미이다.
이 둘은 객체이며 동일하게 메모리공간의 할당과 생성자 호출과정을 거치게 된다는 것이다.
이때도 생성자가 없기 때문에 디폴트 생성자의 호출 과정을 거치게 된다.
그런데 우리가 만든 위 클래스들을 보면 둘다 각각의 생성자를 생성했기 때문에 디폴트 생성자가 생성되지 않았고 호출도 불가능할텐데 Rectangle의 내부에 있는 멤버변수 Point 객체의 경우는 디폴트 생성자를 부르듯이 선언이 되어 있다는
문제가 발생한다.
우리가 아는 수준에서 이걸 해결하기 위해서는 Point 클래스 내부에 디폴트 생성자를 추가해주는 방법 밖에 없다.
그런데 Rectangle 객체가 생성되었을때 그 Rectangle객체 안에 있는 모든 멤버는 의미가 있는 값을 가져야만 한다.
그니까 우리가 받은 Rectangle의 생성자에서 받은 x1, y1, x2, y2로 인자값으로 전달 받은 이유는

결국 Point 클래스에 전달하면서 객체를 생성하기 위함이다.
이를 목적으로 제공되는 문법이 이니셜라이저 라는 것이다.
결론적으로 Rectangle이 Point에 매개변수로 값을 두개 전달받는 생성자를 호출하면서 멤버 변수를 생성하는게 아니라 디폴트 생성자를 호출하면서 멤버변수(객체)를 생성하는 것이 문제이다.
그리고 우리가 원하는대로 Rectangle 생성자로 전달받은 인자들을 통해서 Point 클래스의 우리가 선언한 생성자에 접근하면서 멤버변수를 만들수 있도록 하는게 이니셜 라이져 라는 것이다.
멤버 이니셜라이저 기반의 멤버 초기화

이게 이니셜라이저를 사용한 멤버 초기화 방식이다.
이건 생성자의 정의부쪽 매개변수 뒤로 연결해서 작성하는데 위처럼 쓰인 경우는 객체 upLeft의 생성과정에서 x1과 y1을 인자로 전달받는 생성자를 호출해라, 객체 lowRight의 생성과정에서 x2와 y2를 인자로 전달받는 생성자를 호출해라 라는 의미로 쓰인다.
그래서 이 과정의 순서는
메모리 공간 할당 ---> 이니셜라이저를 이용한 멤버변수(객체)의 초기화 ---> 생성자의 몸체부분 실행
의 순서로 실행된다.
이니셜라이저의 문법을 표준화 한다면
ClassName::ClassName(parameter1, parameter2, ...)
: member1(value1)
, member2(value2)
, member3(value3)
// ...
{
// 생성자 본문
}와 같이 작성해볼 수 있다.
- ClassName - 구현하고자 하는 클래스명
- :: - 범위 지정 연산자로 클래스 이름과 생성자 이름은 연결해서 해당 생성자가 특정 클래스에 속함을 나타냄
- ClassName - 해당 클래스에 정의할 생성자명(클래스명과 동일함)
- (parameter1, parameter2,...) - 생성자에 전달할 매개변수
- : - 이니셜 라이저 리스트를 시작을 알림
- member1 - 생성할 멤버변수의 명칭(객체인 경우)
- (value1) - 맴버변수의 클래스에 선언된 생성자의 매개변수에 맞춰 전달인자를 전달함
물론 이건 함수의 정의부에서 작성하는 내용이다.
이니셜라이저를 이용한 변수 및 상수의 초기화
이니셜라이저를 통해서 객체인 멤버변수의 생성자를 부르는 것 말고도 멤버 변수의 초기화도 가능하다.

이렇게 초기화를 하는 경우 선언과 동시에 초기화되는 형태로 바이너리가 구성된다.
다시 말하면
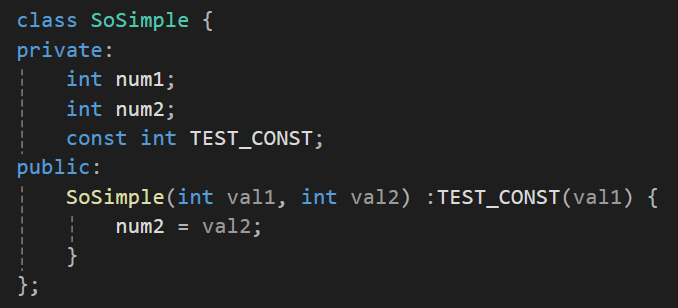
int num1 = n1;과 같이 멤버변수가 선언과 동시에 초기화 된다고 볼 수 있다.
선언과 동시에 초기화가 되는 형태이기에 const로 선언된 멤버변수도 초기화가 가능하다.
멤버변수로 참조자 선언하기
이니셜라이저의 초기화는 선언과 동시에 초기화되는 형태기에 참조자의 초기화도 가능하다.
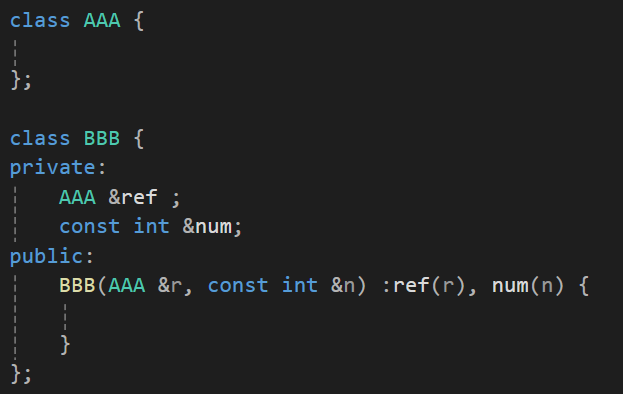
** 참조자는 선언과 동시에 초기화가 되어야하고 const 참조자가 아닌 이상 변수로 초기화가 되어야 한다.
const 참조자는 초기화가 될때 변수뿐만 아니라 상수로도 초기화가 가능하다.
디폴트 생성자
클래스에 생성자를 정의하지 않으면 인자를 받지 않고, 어떤 로직도 처리하지 않는 디폴트 생성자라는 것이 컴파일러에 의해 추가된다.
이렇게 클래스에 생성자가 정의되지 않는다면 컴파일러가

디폴트 생성자를 추가해준다.
그렇기에 모든 객체는 무조건 생성자의 호출 과정을 거쳐서 완성된다.
생성자 불일치
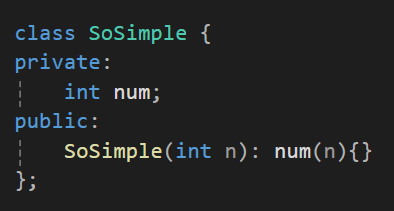
이렇게 생성자를 사용자가 정의했다면 디폴트 생성자는 추가되지 않는다.
SoSimple simObj1(10); // 가능
SoSimple * simPtr1 = new SoSimple(2); // 가능
SoSimple simObj2; // 불가능
SoSimple * simPtr2 = new SoSimple; // 불가능그렇기에 인자를 받지 않는 void 형 생성자의 호출은 불가능하다.
만약 아래와 같은 방식으로 void형 생성자의 호출을 가능하게 하려면
SoSimple simObj1;
SoSimple * simPtr1 = new Simple;별도로 디폴트 생성자 형태의 생성자를 추가로 정의해줘야만한다.
SoSimple (): num(0) {};
private 생성자

이 코드를 보면
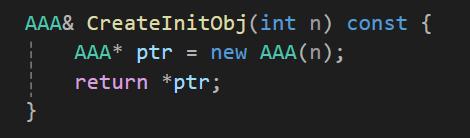
이 함수 내에서 AAA의 생성자중 하나의 인자를 받는 생성자를 찾아 객체를 생성하고자 한다.
그리고 이 생성자는
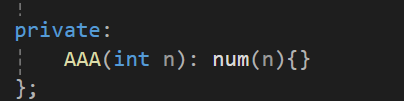
아래에 private로 선언이 되어 있다.
이걸 보면 클래스 내부에서는 private로 선언된 생성자의 호출이 가능함을 알 수 있다.
물론 private이기 때문에 클래스 외부에서는 해당 생성자(전달인자 1개를 받는 생성자)를 호출을 통해서 객체의 생성이 불가능하다.
이 의미는 AAA 클래스의 경우는 전달인자를 하나 받는 생성자를 통해서는 외부에서 직접 객체 생성을 허용하지 않겠다는 의미이다.
소멸자의 이해
소멸자는 생성자와 반대의 기능으로 객체가 소멸할때 호출된다.
그리고 소멸자는 오버로딩이 불가능하다.
소멸자의 경우에는 무조건 인자값을 받지 않도록 정의해야하기 때문이다.
소멸자의 정의법은 클래스의 이름 앞에 ~(틸트)가 붙어서 함수의 이름을 완성하고, 인자값을 받지 않는다.
인자 값을 받지 않아야한다는 말은 오버로딩이 불가능하다는 의미를 뜻함을 알 수 있다.
따라서 하나의 클래스에는 하나의 소멸자만 존재해야한다.

그리고 우리가 명시적으로 소멸자를 정의하지 않으면 생성자와 동일하게 디폴트 소멸자를 삽입해주는데 이 디폴트 소멸자는 하는 일이 아무것도 없다
소멸자의 활용
위에서 말했다 싶이 생성자로 인해 생성된 객체가 소멸될때는 메모리의 정리가 필요한 경우가 있다.
그 경우가 동적으로 할당한 메모리 공간을 제거할때와 같다.
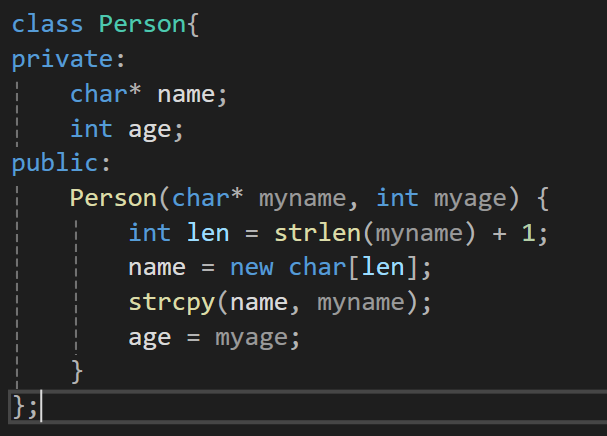
이렇게 Person이라는 클래스의 생성자에서 myname이라는 문자열을 받은 후에 그 길이를 계산하고 그 값을 이용해서 name이라는 맴버변수에 동적으로 메모리공간을 할당해주고, strcpy함수를 사용해서 내용까지 복사해 넣는다.
이렇게 동적으로 메모리 공간이 할당되면(new를 통해서) 반드시 delete 키워드를 사용해서 할당된 공간을 소멸시켜줘야만 한다.
이럴때 소멸자가 필요한 것이다.

이렇게 소멸자 내부에서 동적으로 할당된 메모리공간을 갖고 있는 멤버변수를 소멸시켜주는 역할을 하기에 적절하다.
결론적으로 생성자를 이용해서 할당한 메모리 공간을 소멸시키는 용도로 사용하는 것이 소멸자라고 생각하면 된다.
(물론 그 이상의 기능을 할 수 도 있지만 당장은 이렇게 쓴다고 생각해보자)
Chapter 04-4. 클래스와 배열 그리고 this 포인터
이 주제에서 this 포인터는 개념이 조금 헷갈릴 수 있기에 미리 한번 확인해보고 가자.
this라는 것은 키워드인데, 매우 다양하게 해석이되는 키워드이다.
this는 포인터인데, A라는 클래스와 B라는 클래스를 정의했다고 생각해보자.
그리고 A라는 클래스로 만든 객체를 obj1, B클래스로 만든 객체를 obj2라고 생성했고 각각의 객체 내부에는 this라는 포인터가 존재한다고 가정해보자.
이때 obj1과 obj2객체에 &연산자를 붙여 반환되는 값의 형태는 0x1234와 같은 주소값에 그 객체의 타입정보가 추가된 형태일 것이다.
this는 바로 이 정보를 갖고 있다.
그러면 obj1과 obj2에 m이라는 멤버가 존재한다고 생각해보자.
보통 obj1을 포인터에 담고 m의 값에 접근한다면 주소값 + 객체정보를 가진 포인터를 통해서 접근할 수 있다.
AAA obj1;
AAA * objPtr1 = &obj1;
objPtr1 -> m = 20;//객체의 주소값과 객체의 정보를 가진 objPtr1을 통해 객체의 m에 접근
그런데 아까 말했다 싶이 객체의 this는 obj 포인터와 같은 정보를 담고 있다고 했기에 이 this를 통해서 해당 객체의 멤버변수에 접근도 가능하다.
(이때 this는 클래스의 내부에서만 접근이 가능하다.)
그래서
this -> m = 80;과 같이 접근하면 m의 값을 변경시킬 것이다.
이게 바로 this 포인터이다.
정리하자면 this는 객체 자신을 가리키는 포인터로 해당 키워드가 어디에 쓰였는가에 따라서 그것이 의미하는 값과 타입정보는 달라진다.
객체 배열과 객체 포인터 배열
Person arr[3];
Persion * parr = new Person[3]; // 메모리 공간 동적 할당클래스를 대상으로 배열을 선언할 수 도 있다.
이건 그냥 단순하게 Person이라는 객체 3개가 묶인 배열이다.
그렇기에 길이가 3인 배열의 각각 요소는 다 Person이라는 완성된 객체가 된다.
이 객체가 모두 완성된 객체를 가지기 위해서는 생성자를 호출하는 과정을 거쳐하기 때문에 위 경우에는 void생성자를 통해서 3개의 객체를 생성한 후에 하나의 배열로 묶어준다.
그래서 이걸 객체로 이루어진 배열이라고 해서 객체배열이라고 한다.
그러면
Person * arr[3];
arr[0] = new Person(name, age);
arr[1] = new Person(name, age);
arr[2] = new Person(name, age);와 같은 코드가 있을때 Person * arr[3]은 무엇일까?
arr[3]의 앞에 있는게 이 배열이 담고 있는 요소 하나하나의 타입을 이야기 하는 것이기에 arr에는 Person 객체의 주소값을 담은 포인터 변수가 3개 담겨 있다는 것이다.
그래서 이는 객체의 주소값을 담는 포인터의 배열이라고 해서 객체 포인터 배열이라고 부르고 이 경우에는 별도로 객체를 생성해주는 과정을 거쳐야하기 때문에 각 요소마다 new 연산자를 통해서 각각 객체를 선언해서 그 주소값을 반환해 포인터에 담아 줘야 한다.
그래서 객체 관련 배열을 선언할 때에는 객체 배열을 선언할지 ,아니면 객체 포인터 배열을 선언할지를 먼저 결정해야 한다.
this의 이해
this는 위에서 알아봤듯이 해당 객체의 포인터를 의미하게 된다.
그래서 this로 접근하면 그 객체에 접근한다는 의미이고 그 형태는
ClassName * this;라고 생각하면된다.
다음 예제를 확인해보면 조금 더 명확하게 알 수 있다.
먼저 클래스를 하나 선언해보자.

이렇게 ClassName이라는 클래스를 하나 선언했다고 보자.
헤당 클래스는 객체를 생성하면서 생성자를 호출하면 멤버변수인 num에 전달 인자 n을 집어 넣고 그 값을 출력한다.
또한 this의 값을 출력한다.
그리고 ShowClassData를 호출하면 지금 현재 멤버 변수 num의 값을 반환한다
마지막으로 GetThisPointer라는 함수를 호출하면 this를 반환한다.
이게 이 클래스를 사용해서 main을 구현해보자면,
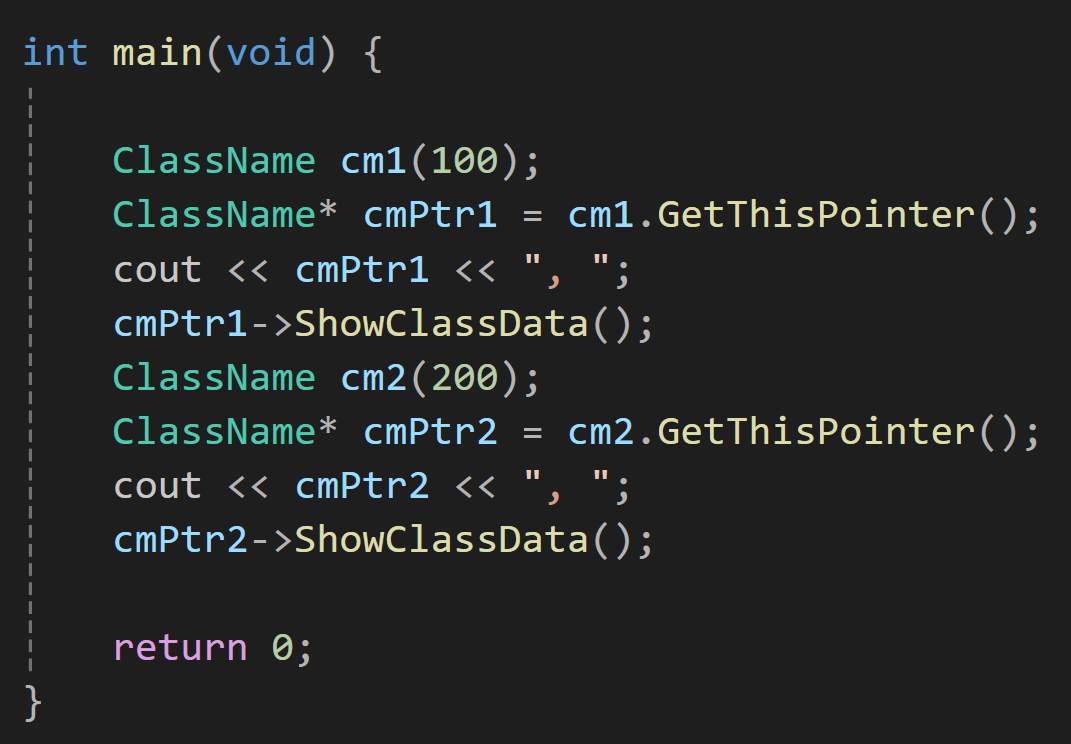
객체를 생성하면서 100을 전달하고 그 주소값과 값을 출력한다.
그리고 생성한 객체의 this값을 cmPtr1에게 전달해주면서 cmPtr1의 값을 출력한다.
이는 cmPtr1에 담긴 this의 값으로 포인터이기 때문에 주소값을 저장하고 있을 것이다.
그리고 나서 ShowClassData를 한번 조회한다.
추가로 하나의 객체에 대해서도 같은 로직을 진행한다.
그 결과로 출력된 내용은
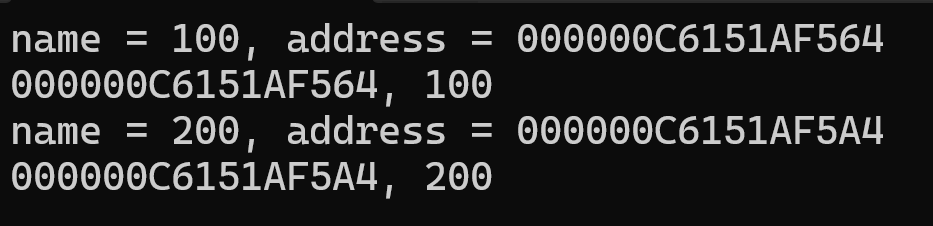
이러하다.
이렇게 this는 각각의 객체에 별도의 값을 갖고 있고 그 값은 항상 고정된 값이 아니라 유동적인 값임을 알 수 있다.
this 포인터의 활용
그러면 이제 this는 주소값을 갖고 있는 클래스 포인터임을 확인했다.
그렇기에 this를 사용하는 방법도 클래스 포인터의 사용법처럼 화살표 연산자를 통해 멤버변수에 접근하던가 * 참조연산자와 .연산자를 통해서 멤버변수에 접근해서 사용할 수 있다.
class ClassName {
private:
int num1;
int num2;
public:
TwoNumber (int num1, int num2){
this -> num1 = num1;
this -> num2 = num2;
}
}여기서 this -> num1은 결국 멤버변수 num1을 의미한다.
객체의 주소값으로 접근할 수 있는 대상은 지역변수가 아니라 멤버변수이기 때문이다.
그니까 this -> num1 = num1에서 앞에 this -> num1은 멤버변수 num1이고 = num1에서의 num1은 매개변수 num1을 지칭한다.
그래서 사실 위에 함수 TwoNumber의 경우는
TwoNumber (int num1, int num2) : num1(num1), num2(num2){
//로직없음
}과 같이 구현해도 동일한 기능을 한다.
그래서 사실 이렇게 헷갈리게 이름을 작성하는건 좋지 않으니 매개변수의 이름과 맴버변수의 이름은 겹치지 않게 작성해주는 것이 좋다.
Self-reference의 반환
this에 * 역참조 연산자를 붙이면 결국 해당 객체 그자체를 의미한다.
거기에 참조자를 통해서 외부로 반환하게 된다면 그 반환값은 그 객체 자체가 될것이다.
예제를 보면
class ClassName {
private:
int num;
public:
ClassName(int n) : num(n){
cout << "객체생성" << endl;
}
ClassName& Adder (int n){
num += n;
return *this;
}
ClassName& ShowTwoNumber(){
cout << num << endl;
return *this;
}
};여기서 *this를 반환하고 이걸 ClassName&의 참조자 형태로 반환하겠다고 함수를 선언하면 지금 보는 그 객체 자체를 반환한다고 보면 된다.
이걸 실행쪽에서 확인하면 이해가 좀 더 쉬울 수 도 있는데
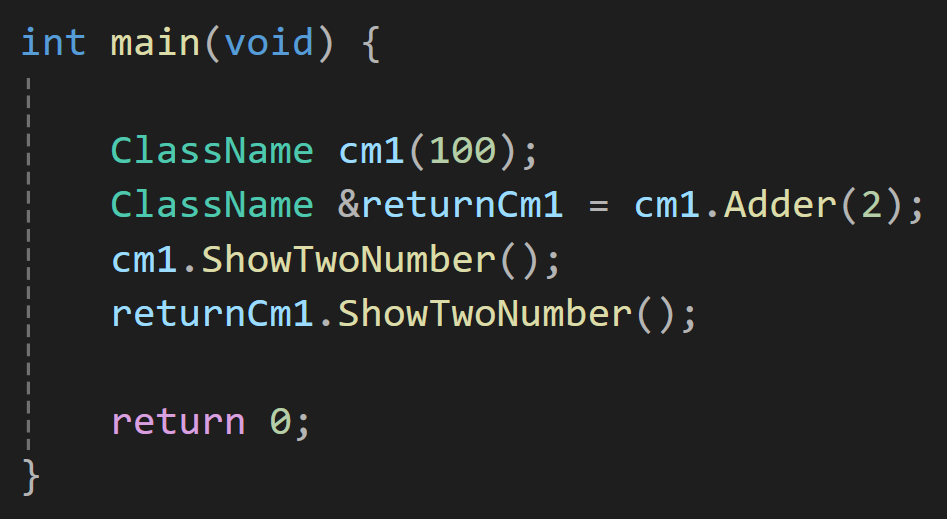
이렇게 선언하면 *this를 참조자 형태로 반환하기에 사실 cm1과 returnCm1은 같은걸 의미하게 된다.
그래서 cm1과 returnCm1이 같이 ShowTwoNumber를 호출해보면

같은 내용을 호출하는 것을 볼 수 있다.
한번 더 값을 변경해보면
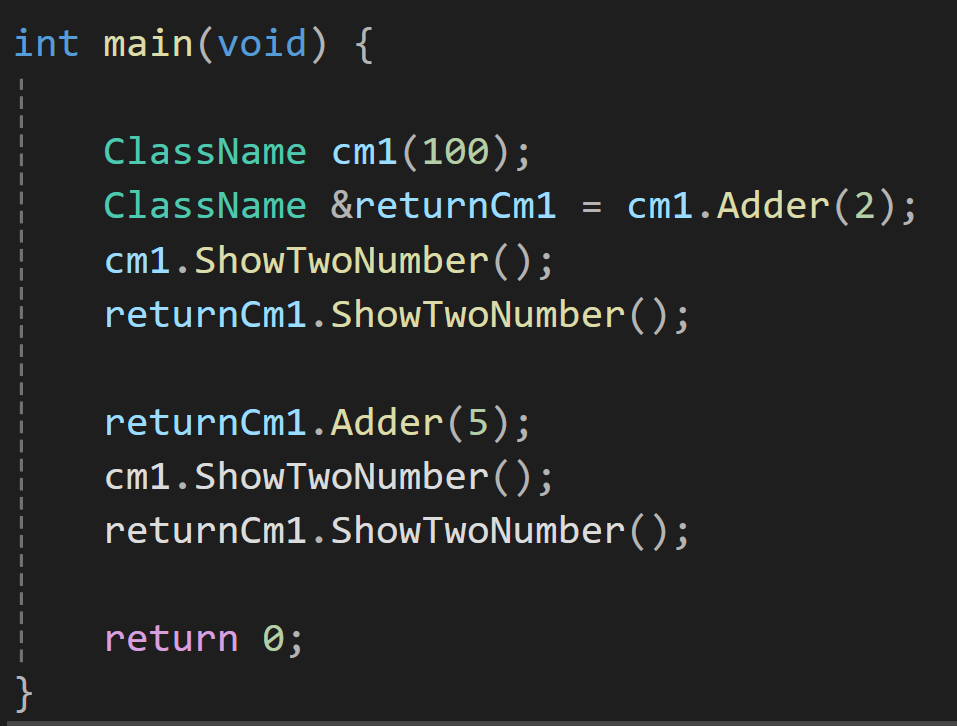

이렇게 returnCm1의 참조값이 결국 cm임을 알 수 있다.
그런데 만약

참조값이 아니라 그냥 객체 형태로 받으면 어떻게 될까
이는 참조가 아니라 그냥 복사하는 개념으로 첫번째 호출에서는 값을 변화하고 전달하기 때문에 값이 동일할 수 있으나 returnCm1이나 cm1을 통해서 Adder을 호출해서 값을 변화 시키면 그 차이를 알 수 있게 된다.


이는 복사해서 사용하는 것과 참조해서 사용하는 차이점이 있다.
참조자에 대해서 이해가 부족하니까 이런 점들을 자꾸 찝어가면서 공부하는것 같기도하다.
이 부분도 추가적으로 복습이 필요하다고 생각한다.
어렵다면 다시 한번 찾아보고 다시 한번 공부하고 오자.
'Programming Language > C++' 카테고리의 다른 글
| 열혈 C++ - Chapter 03. 클래스의 기본 (0) | 2024.11.19 |
|---|---|
| 열혈 C++ - Chapter 02. C언어 기반의 C++ 2 (0) | 2024.11.19 |
| 열혈 C++ - Chapter 01. C언어 기반의 C++ (0) | 2024.11.18 |